|
Michele MErler |
|
Office : 624 CEPSR
Office Phone: 212-939-7071
Email: mmerler AT cs DOT Columbia DOT edu
|
|
Contact |


|
Click me |
|
I am interested in helping users efficiently and effectively access information and learn from online multimedia sources, in particular unstructured, “wild” videos. I am convinced that we can do better than Youtube both from the retrieval and browsing points of view !
Indexing Presentation Videos based on Semantic Content
Videos of presentations are tools nowadays employed in a large variety of systems for different purposes, spanning from distance or e-learning to automatic generation of conference proceedings, from corporate talks to student presentations. A quickly increasing quantity of these videos is already available and retrievable from the web. A great tool for example is videolectures.net ! Finding efficient tools to solve the problem of effectively summarizing, indexing, cross-referencing, displaying and browsing this type of videos becomes crucial to the end of exploiting such growing resources and of obtaining my PhD. Simply using tag-based searches and presenting the video recordings by themselves is not sufficient in many cases. Unlike television broadcasts or movies, the videos we deal with do not present any structure, as they are not recorded by professional cameramen, they are not edited, and due to compression and streaming purposes their quality is low. I am building a system where a user can search for a presentation from professor X on topic Y, which contains graph Z, and our browser returns an enhanced representation of the relative video shot.
Text in slides
Slides consist in a natural way of segmenting presentations, since the speakers thoughtfully prepared and conferred a specific semantic meaning to each of them. Studies have been conducted in order to assess the reliability of slides as a summarization tool. We use changes of text in the slides as a means to segment the video into semantic shots. Unlike precedent approaches, our method does not depend on availability of the electronic source of the slides, but rather extracts and recognizes the text directly from the video. Once text regions are detected within keyframes, a novel binarization algorithm, Local Adaptive Otsu (LOA), is employed to deal with the low quality of video scene text, before feeding the regions to the open source Tesseract1 OCR engine for recognition.
Related Publication at ICIP09 (poster)
Face Indexing
We propose a system to select the most representative faces in unstructured presentation videos with respect to two criteria: to optimize matching accuracy between pairs of face tracks, and to select humanly preferred face icons for indexing purposes. We first extract face tracks using state-of-the-art face detection and tracking. A small subset of images are then selected per track in order to maximize matching accuracy between tracks. Finally, representative images are extracted for each speaker in order to build a face index of the video. Using an optimal combination of 3 user preference measures (amount of skin pixels, pose and resolution), we efficiently build face indexes containing the speakers starting from the tracks.
Related Publication at ACM Multimedia11
Enhance Semantic Shots Visualization
We want to build mosaics with a feature based approach. On one hand, text recognition can benefit from this approach, since superresolution techniques could be used to improve the quality of the text to be analyzed once overlapping frames have been registered. On the other hand, mosaics are a meaningful representation of semantic content that situates it into its video context and therefore goes beyond the usual keyframe or video playback based displays. We want to integrate mosaics with the other representations and enhance them by highlighting, enlarging, crispening and superimposing meaningful text and diagrams on them. Some systems try to offer a clearer visualization by simply presenting a copy of the electronic slides besides the window with the video playback or directly enhance the video by superimposing the slides on the proper regions. Besides relying on slides templates, such systems introduce a split-attention effect, where two areas of the screen (one with the slides, another with a small video of the presenter) are competing for the viewer’s attention. Our approach overcomes both limitations by being "unsourced", in the sense that it works without any slide template to be compared, and with the use of mosaics. We will also be able to investigate the extent to which user control over mosaic highlighting aids comprehension and search of semantic concepts. A poster showing this concept can be found hanging on the 6th floor of the Shapiro building at Columbia or by clicking here.
Large Scale Image/Video Retrieval
Here is a summary of my attempts to detect and retrieve concepts and events from large collections of videos “in the wild”, such as the ones that can be found on Youtube. These videos are challenging to analyze and index not only because of their content diversity (in recording devices, content, camera motions, production styles, settings, compression artifacts etc.) and lack of structure, but also for their remarkable growing quantity, For example, on Youtube alone, 35 hours of video are uploaded every minute, and over 700 billion videos were watched in 2010 !
Semantic Model Vectors
In order to bridge the notorious semantic gap between low level features and high level concepts (or events) in videos, we propose Semantic Model Vectors, an intermediate level semantic representation, as a basis for modeling and detecting complex events in unconstrained real-world videos, such as those from YouTube. The Semantic Model Vectors are extracted using a set of discriminative semantic classifiers, each being an ensemble of SVM models trained from thousands of labeled web images, for a total of 280 generic concepts. Our study reveals that the proposed Semantic Model Vectors representation outperforms—and is complementary to—other low-level visual descriptors for video event modeling. We hence present an end-to- end video event detection system, which combines Semantic Model Vectors with other static or dynamic visual descriptors, extracted at the frame, segment or full clip level.
[Project page] and related Publication in IEEE Transactions on Multimedia
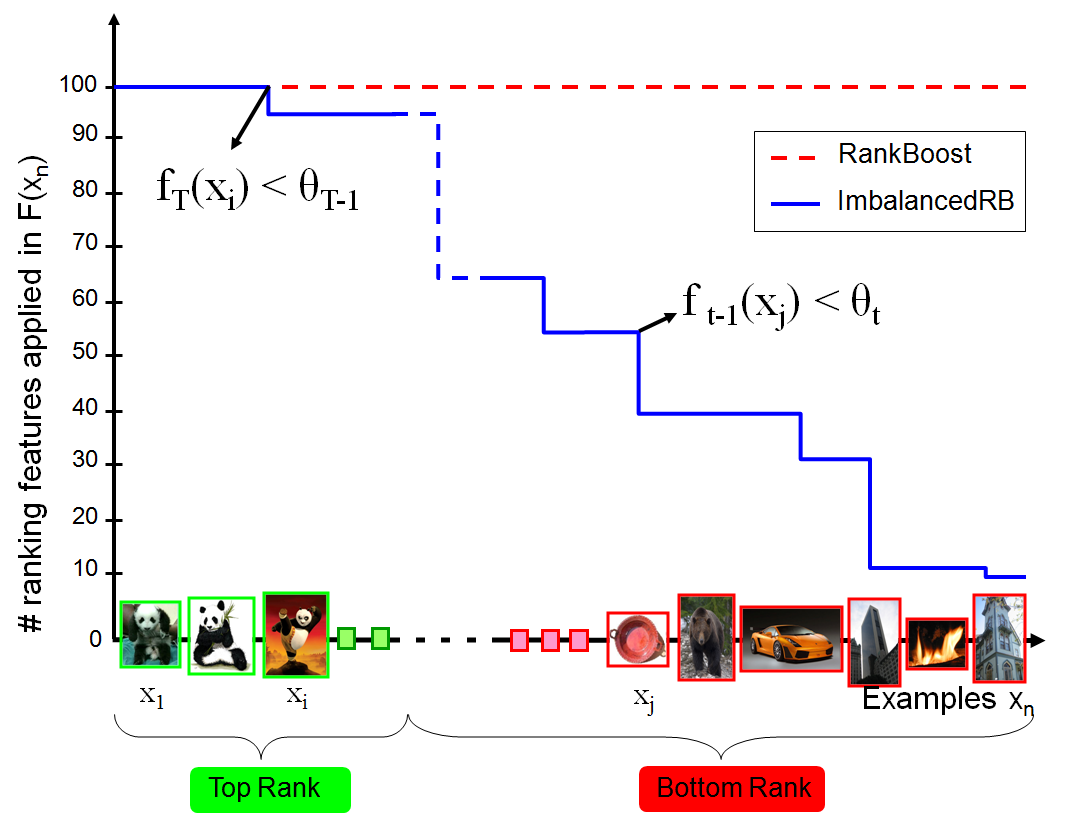
Imbalanced Rankboost
Ranking large scale image and video collections usually expects higher accuracy on top ranked data, while tolerates lower accuracy on bottom ranked ones. In view of this, we propose a rank learning algorithm, called Imbalanced RankBoost, which merges RankBoost and iterative thresholding into a unified loss optimization framework. The proposed approach provides a more efficient ranking process by iteratively identifying a cutoff threshold in each boosting iteration, and automatically truncating ranking feature computation for the data ranked below.
Related Publications at CVPR09 (poster) and LSMM@ACM MM09.
TRECVID
I have taken part three times to the IBM team participating to the TREC Video Retrieval Evaluation sponsored by the sponsored by the National Institute of Standards and Technology. I actively participated to the High Level Feature extraction, Copy Detection and Multimedia Event Retrieval tasks.
You can look at our workshop notebook papers from 2008 , 2009 and 2010
Past Projects and Fun Stuff
Grocery Shopping Assistant for the Visually Impaired ( @ UCSD )
While I was at UCSD I spent some time working on the really cool GROZI project. The objective was to help visually impaired people find a list of groceries in a convenience store with the help of a handheld device containing a camera and running object recognition. I worked on the object detection/recognition part, trying to match in vitro images (taken from the web) to the in situ video feed from the handheld device.
We published preliminary results at the SLAM workshop of CVPR07. Here is the paper.
This work was the basis for my MS thesis at the University of Trento. Here are the slides of my presentation.
I also presented the work at ICVSS07. Here is the poster.
Breaking an Image Based CAPTCHA
I have always found CAPTCHAs a fascinating idea. Recently there has been some interest in image based ones (instead of the traditional text based ones). But are they reliable? As my project for the Computational Photography class I took here at Columbia, I tried to break a (still working at the time) commercial image based CAPTCHA: VidoopCaptcha, by using simple image processing techniques and training images from collected from the web. It turns out image based CAPTCHAs are still not reliable enough. I guess not everyone can be Luis Von Ahn…
Here is the project webpage and our presentation. |