Michele Merler, Bert Huang, Lexing Xie, Gang Hua and Paul Natsev
[Paper] [Video Events] [System Overview] [Semantic Model Vectors] [Results] [Data]
Abstract:
We propose Semantic Model Vectors, an intermediate level semantic representation, as a basis for modeling and detecting complex events in unconstrained real-world videos, such as those from YouTube. The Semantic Model Vectors are extracted using a set of discriminative semantic classifiers, each being an ensemble of SVM models trained from thousands of labeled web images, for a total of 280 generic concepts. Our study reveals that the proposed Semantic Model Vectors representation outperforms—and is complementary to—other low-level visual descriptors for video event modeling. We hence present an end-to-end video event detection system, which combines Semantic Model Vectors with other static or dynamic visual descriptors, extracted at the frame, segment or full clip level. We perform a comprehensive empirical study on the 2010 TRECVID Multimedia Event Detection task, which validates the Semantic Model Vectors representation not only as the best individual descriptor, outperforming state-of-the-art global and local static features as well as spatio-temporal HOG and HOF descriptors, but also as the most compact. We also study early and late feature fusion across the various approaches, leading to a 15% performance boost and an overall system performance of 0.46 Mean Average Precision.
Paper:
Michele Merler, Bert Huang, Lexing Xie, Gang Hua and Apostol Natsev. Semantic Model Vectors for Complex Video Event Recognition. to appear in IEEE Transactions on Multimedia, Special Issue on Object and Event Classification in Large-Scale Video Collections, 2012. [PDF (preprint)] [bibtex]
Video Events:
Our attention is on videos “in the wild”, where a typical video is Youtube-like, often generated by users in unconstrained environment. The challenges posed by these tyoe of videos originate from the significant variety of quality, viewpoint, illumination, setting, compression, etc. as evident in the following Figure. The definitions of the video events we analyze, as posted on the TRECVID MED official site, are the following:
Most existing approaches and datasets for video event recognition focus on building classifiers for short actions through spatio-temporal features and for concepts based on low-level visual descriptors extracted from keyframes. Complex video events however cannot be described by a single action or keyframe. For example, the category Making a cake comprises multiple actions (mixing, inserting into oven, tasting) which involve different interactions between primitive semantics (people and objects) over extended periods of time. Therefore, a complex representation which involves such semantic primitives is needed.

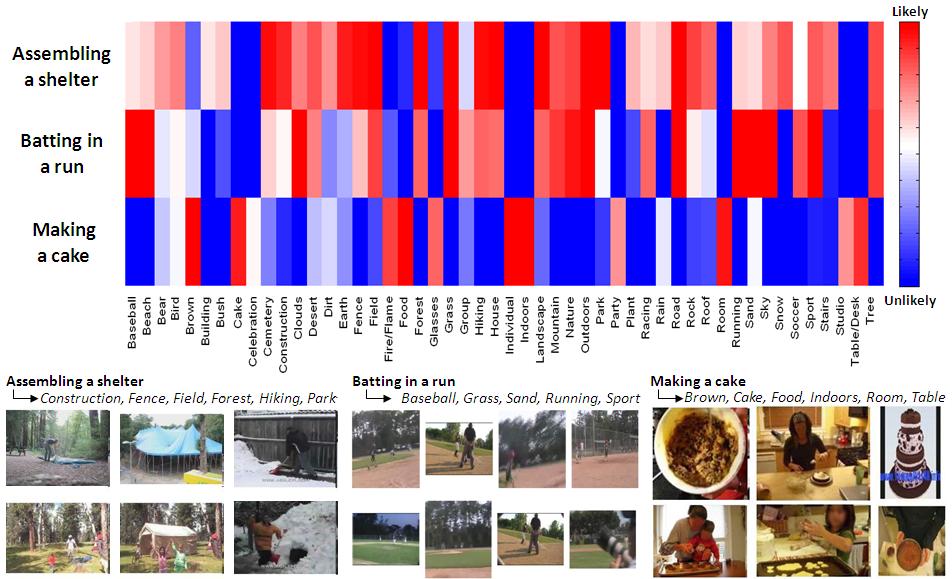
Examples from the 2010 TRECVID MED video event categories: assembling shelter (top), batting in run (middle) and making cake (bottom). Note the significant variety of quality, viewpoint, illumination, setting, compression, etc. both intra and inter categories.
System overview:
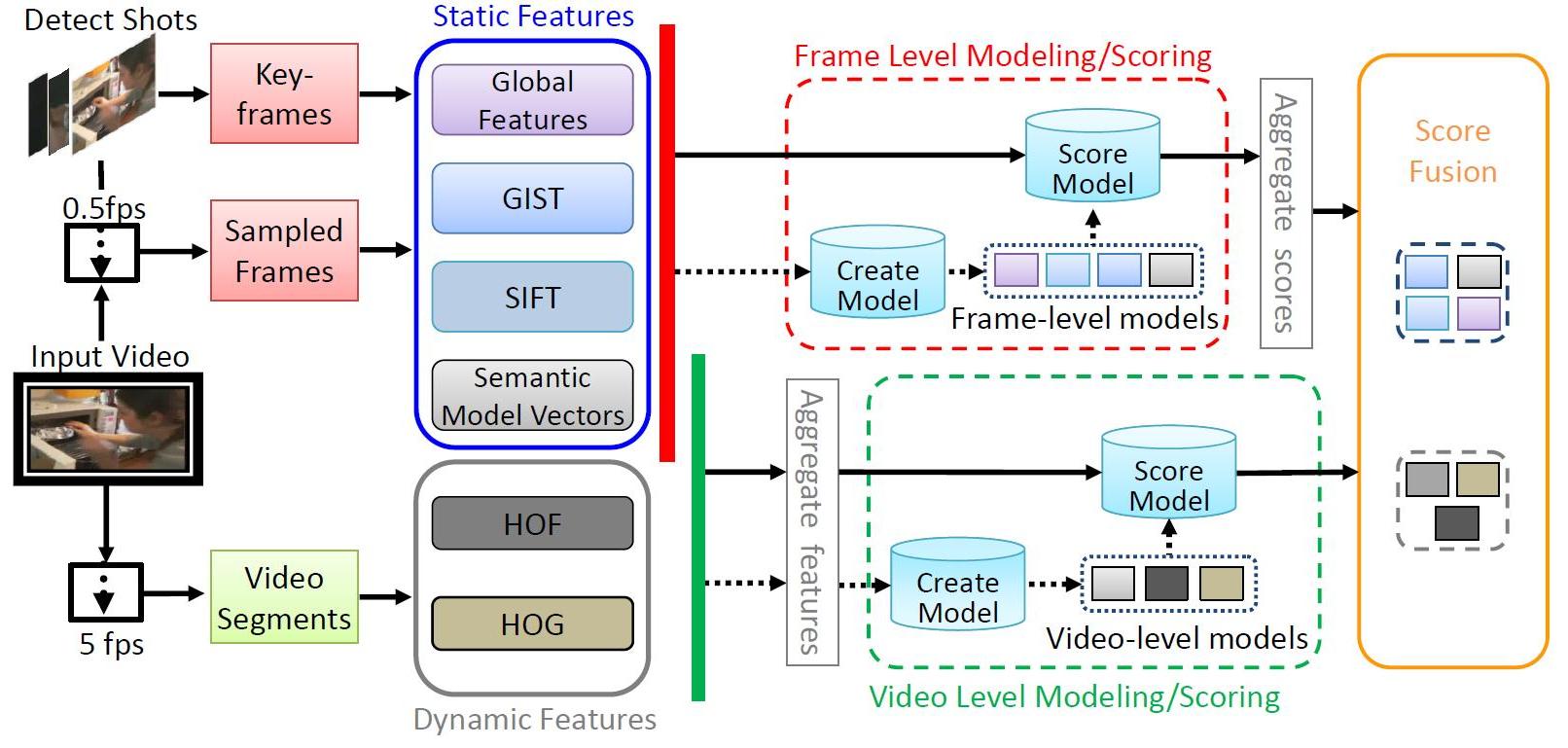
Our event detection system includes a variety of approaches. This allows us to explore effective methods for the new multimedia event detection domain, and forms the basis of a comprehensive performance validation. An overview of our event detection system is shown in the Figure, and there are four main parts for processing and learning (roughly from left-toright in the layout): video processing, feature extraction, model learning and decision aggregation. We employ descriptors that inherently complementary under different perspectives:
We also tested different temporal dimensions (keyframes, uniformly sampled frames, entire video) in terms of both feature extraction and prediction scores fusion, with alternatives between early and late fusion..
Semantic Model Vectors:
 We propose an intermediate semantic layer between low-level features and high-level event concepts in order to bridge the
notorious semantic gap. This representation, named Semantic Model Vectors, consists of hundreds of discriminative semantic
detectors, each coming from an ensemble SVMs trained from a separate collection of thousands of labeled web images,
from a common collection of global visual features. These semantic descriptors cover scenes,
objects, people, and various image types.
Each of these semantic dimensions provides the ability to discriminate among lowlevel and mid-level visual cues, even if such discrimination is
highly noisy and imperfect for a new data domain.
The Semantic Model is an ensemble of SVMs with RBF kernel learned from a development set of thousands of manually
labeled web images, which were randomly partitioned into three collections: 70% as the training set, 15% as the validation
set, and 15% as the held-out set. The number of feature types from which each of the individual SVMs are learned was 98,
by means of computing 13 different global visual descriptors including color histogram, color correlogram, color moment,
wavelet texture and edge histogram at up to 8 granularities (i.e., global, center, cross, grid, horizontal parts, horizontal
center, vertical parts and vertical center).
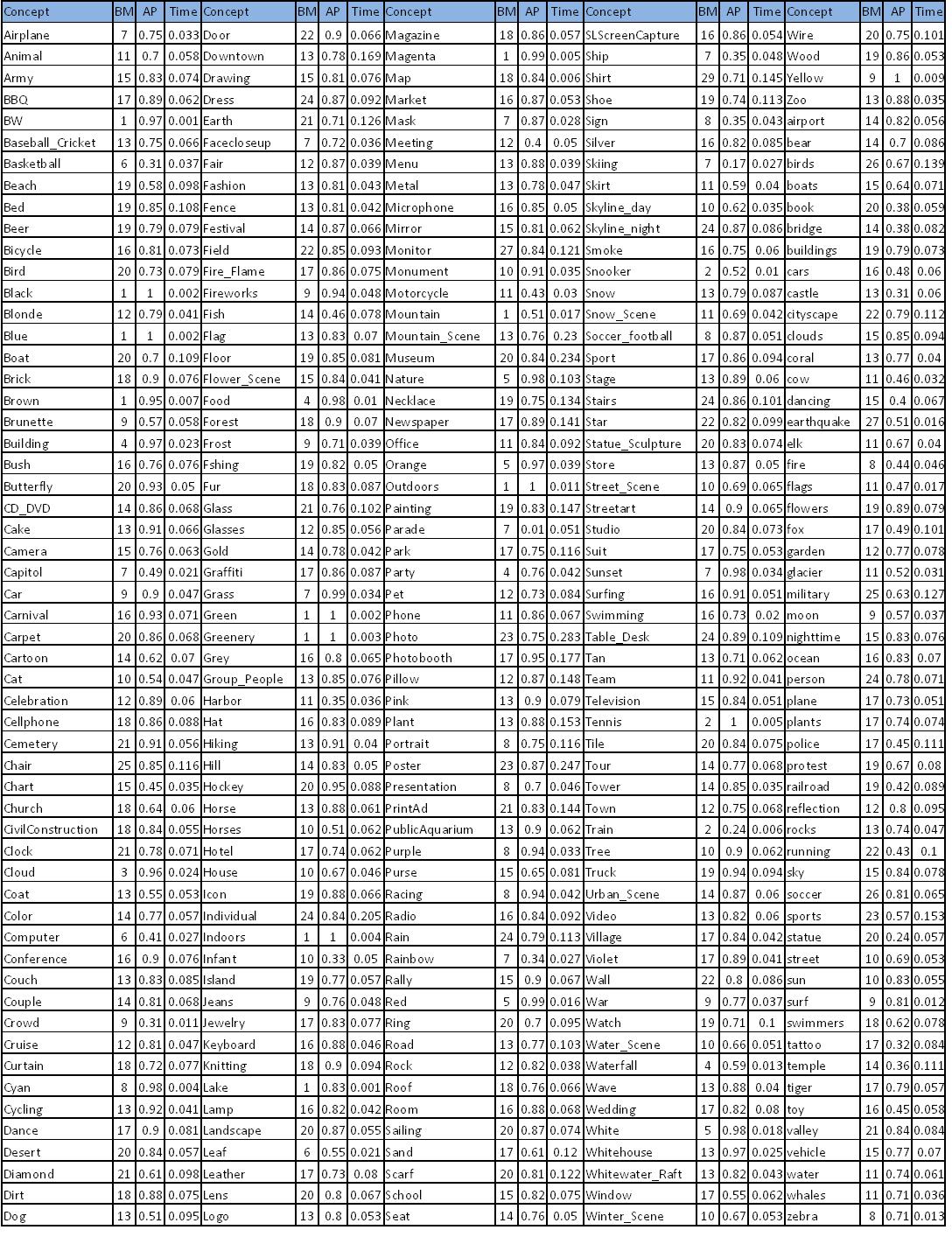
By clicking on the Figure you can see the list of 280 Semantic Models, with BM: number of base models (bags) used to generate
the ensemble SVMs, AP: average precision cross validation score obtained during the training process, and Time: prediction
score extraction time (in seconds).
We propose an intermediate semantic layer between low-level features and high-level event concepts in order to bridge the
notorious semantic gap. This representation, named Semantic Model Vectors, consists of hundreds of discriminative semantic
detectors, each coming from an ensemble SVMs trained from a separate collection of thousands of labeled web images,
from a common collection of global visual features. These semantic descriptors cover scenes,
objects, people, and various image types.
Each of these semantic dimensions provides the ability to discriminate among lowlevel and mid-level visual cues, even if such discrimination is
highly noisy and imperfect for a new data domain.
The Semantic Model is an ensemble of SVMs with RBF kernel learned from a development set of thousands of manually
labeled web images, which were randomly partitioned into three collections: 70% as the training set, 15% as the validation
set, and 15% as the held-out set. The number of feature types from which each of the individual SVMs are learned was 98,
by means of computing 13 different global visual descriptors including color histogram, color correlogram, color moment,
wavelet texture and edge histogram at up to 8 granularities (i.e., global, center, cross, grid, horizontal parts, horizontal
center, vertical parts and vertical center).
By clicking on the Figure you can see the list of 280 Semantic Models, with BM: number of base models (bags) used to generate
the ensemble SVMs, AP: average precision cross validation score obtained during the training process, and Time: prediction
score extraction time (in seconds).
Results:
We evaluated the different approaches outlined in the previous Sections on the 2010 TRECVID MED corpus, which presents a strong imbalance between positive (~50 per category) and negative (~1600) examples in both development and test sets. Hence, in order to measure the performance of each model, we adopted a suitable metric which is the average precision (AP). Interestingly, the proposed Semantic Model Vectors outperform all the other features in terms of Mean Average Precision (0.392), independently from the sampling adopted. Considering the large scale nature of the video event recognition problem at hand, the space occupied by the feature representation of each video is crucial. Semantic Model Vectors can represent an entire video with its 280 dimensional feature vector (after the feature frames to video aggregation), and results to be not only the best performing descriptor in terms of MAP, but also the most compact in terms of number of kilobytes (KB) necessary to represent each video. SIFT, which is the second best performing descriptor in term of MAP, occupies approximately 15 times the space required by Semantic Model Vectors. In our experiments for each descriptor, early fusion at feature level, consisting in average or max pooling from frame to video descriptor, proved to perform better than late fusion, where predictions on individual frames are aggregated to score an entire video.
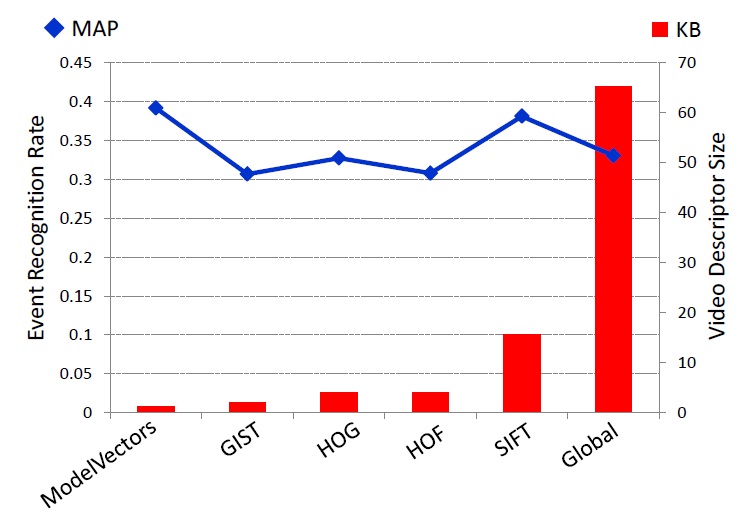
Mean Average Precision vs. Video descriptor size (in kilobytes) based on individual video descriptors. Semantic Model Vectors offer the most compact representation as well as the best recognition performance. |
Semantic Model Vectors are extracted at every keyframe, thus require a fusion from frame level to video level. Fusing features from keyframes into a single descriptor per video and learning a classifier on top of it performs significantly better than learning a classifier directly on the frames and then aggregating the predictions from all the frames into a score for the entire video. |
Given the complementary nature of the descriptors and methods adopted, their combination naturally leads to a significant performance improvement.
Retrieval performance of different event recognition approaches based on individual features (lighter colors) and their combinations (darker colors). Average precision computed for each category and MAP over the whole 2010 TRECVID MED dataset.
Data:
The following file contains Semantic Model Vectors for the Trecvid MED 2010 dataset. Please refer to the README for instructions/description on how to use them.
Download (~200 MB compressed)
Trecvid Official Reference:
@inproceedings{1178722,
author = {Alan F. Smeaton and Paul Over and Wessel Kraaij},
title = {Evaluation campaigns and TRECVid},
booktitle = {{MIR} '06: {P}roceedings of the 8th {ACM} {I}nternational {W}orkshop on {M}ultimedia {I}nformation {R}etrieval},
year = {2006},
isbn = {1-59593-495-2},
pages = {321--330},
location = {Santa Barbara, California, USA},
doi = {http://doi.acm.org/10.1145/1178677.1178722},
publisher = {ACM Press},
address = {New York, NY, USA},
}