Brief Notes on Computer Word and Byte Sizes
This is not my usual blog fodder, but there’s too much material here for even a Mastodon thread. The basic question is why assorted early microcomputers—and all of today’s computers—use 8-bit bytes. A lot of this material is based on personal experience; some of it is what I learned in a Computer Architecture course (and probably other courses) I took from one of my mentors, Fred Brooks.
There are three starting points important to remember. First, punch card data processing is far older than computers: it dates back to Hollerith in the late 19th century. When computerization started taking place, it had to accommodate these older “databases”. Second, early computers had tiny amounts of storage by today’s standards, both RAM and bulk storage (which may have been either disk (for some values of “disk”!) or tape). Third, until the mid-1960s, computers were either “commercial” or “scientific”, and had architectures suited for those purposes.
Punch card processing was seriously constrained. Punch cards (at least the IBM type; there were competing companies) had 80 columns with 12 rows each. There was a strong desire to keep all data for a given record on a single card, given the way that data processing worked in the pre-computer era (but that’s a topic for another time). This meant that there was a premium on ways to compress data, and to compress it without today’s software-based algorithms. The easiest way to do this was to put extra holes in a card column. Consider a column holding a single digit “3”. That was represented by a single hole in the 3-row of a single column. There were thus 10 rows reserved for digits—but in a numeric field, the 11-row and the 12-row weren’t used. You could encode two more bits in that colum, as long as the “programming” knew that, say, a column with a 12-3 punch was really a 12 punch and the number 3 and not the letter C. Clearly, 10 digit rows plus two "zone" rows gives us 40 possible characters; a few more were added when things were computerized.
Let’s look at such computers. The underlying technology was binary, because it’s a lot easier to build a circuit that looks at on/off rather than, say, 10 different voltage levels. When reading a card, though, you had to preserve the two zone bits separately, because their meaning was application-dependent. Accordingly, they used 6-bit characters: two zone bits, plus four bits for a single digit. But you can fit 16 possible values in those four bits, not just 10, so machines of that era actually had 64-bit character sets. In a purely numeric field, the zone bits were used for things like the sign bit and (sometimes) for an end-of-field marker of some sort, but that’s not really relevant to what I’m talking about so I won’t say more about those. The important thing is that each column had had to be read in as a single character, more or less uninterpreted.
Representing a number as a string of (effectively) decimal characters was also ideal for commercial data processing, where you’re often dealing with money, i.e., with dollars and cents or francs and centimes. It turns out that $.10 can’t be represented in binary: 1/10 is a repeating string in binary, just like 1/3 is in decimal, and CFOs and bankers didn’t really like the inaccuracy that would result from truncating values at a finite number of places. (Pounds, shillings, and pence? Don’t go there!) The commerical computers of the day, then, would do arithmetic on long strings of decimal digits.
Scientic computers had a different constraint. They were often dealing with inexact numbers anyway (what is the exact diameter of the earth when computing an orbit), and had to deal with logarithms, trig functions, and more. Furthermore, many calculations were inherently imprecise: a Taylor series won’t yield an exact answer except by chance, and it might not be possible even in theory. (What is the exact value of π? It’s not just irrational, it’s transcendental.) But there were other constraints. Sometimes, scientists and engineers were dealing with very large numbers; other times, they were dealing with very small numbers. Furthermore, they needed a reasonable amount of precision, though just how much was needed would vary depending on the problem. Floating point numbers were represented internally in scientific notation: an exponent (generally binary) and a mantissa. There were thus two critical parameters: the number of bits in the mantissa, which translated into the precision of numbers stored, and the number of bits in the exponent, which translated into the range. (Both fields, of course, included a sign bit in some form.) Given these constraints, and given that commercial data processing, with its 6-bit characgters, came first, it was natural to use 36-bit words: plently of bits of precision and range, and the ability to hold six characters if that’s what you were doing.
That’s where matters stood when the IBM S/360 series was being designed starting in 1961. But one of the goals of the 360s was to have a single unified architecture that could do both scientific and commerical computing. There was still the need to support those old BCD databases, whether they were still on punch cards or had migrated to magetic tape, and there was still the need to support decimal arithmetic. The basic design was for a machine that could support memory-to-register arithmetic for scientifc work and general utlity computing, and storage-to-storage decimal arithemtic for commercial computing. This clearly implied a hybrid byte/word architecture. But how big should bytes be? One faction favored 6-bit bytes and either 24-bit or 36-bit words; another favored 8-bit bytes and 32-bit words. Ultimately, Brooks made the call: 8-bit bytes permitted lower-case letters, which he foresaw would become important to permit character processing. (Aside: Brooks, apart from being a mensch, was a brilliant man. It’s sobering to realize that he was appointed to head the S/360 design project, a bet-the-compay effort by IBM, when he was just 30 years old, and this was just after his previous project, the 8000 series of scientific computers, was canceled. I wasn’t even out of grad school when I was 30!)
The reduction from 36 bits to 32 bits for floating point numbers was challenging: there was a loss of precision. You could go to double-precision floating point—64 bits—but that cost storage, which was expensive. In fact, 8-bit bytes were also expensive: 33% more bits for each character. (IBM did many simulations and analyses to confirm that 32 bits would usually suffice.) But Brooks’ vision of the need for lower case letters has been amply confirmed. (Other character sets than the American Latin alphabet? Not really on folks’ radar then, which was unfortunate. But it would have been hard to do something like Unicode back then. The lowest plane of Unicode is based on ASCII, not IBM’s EBCDIC. Many people within IBM wanted to go to ASCII for the S/360 line (there was even support in the Program Status Word for ASCII bytes instead of EBCDIC ones when dealing with decimal arithmetic), but major customers begged IBM not to do that—remember those pesky zone punches that still existed and that still couldn’t be converted in a context-independent fashion?)
8-bit bytes have other, albeit minor, advantages. If you’re trying to create a bit array, it’s nice to be able to lop off the lower-order 3 bits and use them to index into a byte. But Brooks himself said that the primary reason for his decision was to support lower-case letters. (Aside: Gerritt Blaauw, one of the other architects of the S/360, spent a semester at UNC Chapel Hill where I was a grad student, and I took a course in computer design from him. There were rumors in the trade press that IBM was going to switch to 9-bit bytes for future computers. I happened to overhear a conversation between him and Brooks about this rumor. Neither knew if it was true, but they both agreed that it would be unfortunate, given how hard they’d had to fight for 8-bit bytes.) USASCII fits nicely into 7 bits, but that’s a really awkward byte size. The upper plane was used for a variety of other alphabets’ characters. That usage, though, has largely been supplanted by Unicode. What it boils down to is that every since the S/360, there has never been a good reason to use a byte size of anything other than 8 bits. On IBM systems, you have EBCDIC, an 8-bit character set. On everything else, you have ASCII, which fits nicely in 8 bits and was more international.
Word sizes are more linked to hardware. The real issue, especially in the days before cache, was the width of the memory bus. A wide bus is better for performance, but of course is more expensive. The S/360 was originally planned to have five models, from the low-end 360/30 to the 360/70, that shared the same instruction set. It turns out that the 360/50 was a sweet spot for price/peformance and for profit—and it had a 32-bit memory bus. If you’re trying to do a 32-bit addition, you really want the memory operand to be aligned on a 4-byte boundary, or you’d have to do two memory fetches. 32 bits, then, is the natural word size, and the size of the registers. You could do half-word fetches, but that’s easy; you just discard the half of the word you don’t want. A double-precision 64-bit operand requires two fetches, but on a higher-end machine with a 64-bit bus it’s only one fetch if the operand is aligned on an 8-byte boundary. And on the IBM Z series, the modern successor to the S/360? Words are still 32 bits, because the nomenclature is established. A pair of 64-bit registers together is said to hold a “quadword”. That is, what a “word” is is was defined by the original history of the architecture; after that, it’s likely historical.
In Memoriam: Frederick P. Brooks, Jr. --- Personal Recollections
Fred Brooks passed away on November 17. He was a giant in computer science and a tremendous inspiration to many of us.
Brooks is famous for many things. Many people know him best as the author of The Mythical Man-Month, his musings on software engineering and why it’s so very hard. Some of his prescriptions seem quaint today—no one these days would print out documentation on microfiche every night to distribute to developers—but his observations about the problems of development remain spot-on. But he did so much more.
He started his career at IBM. One of his early assignments was to NSA; among other things, when back at IBM he worked on the design of Harvest, the character-processing auxiliary processor to the IBM 7030. (When I took computer architecture from him, I learned to recognize some characteristics that made for a good cryptanalytic machine. He, of course, was working back in character cipher days, but it’s remarkable how many of those same characteristics are useful for attacking modern ciphers.)
He was also a lead on a failed project, the IBM 8000 series. He tried to resign from IBM after it failed; Watson replied, "I just spent a billion dollars educating you; I’m not letting you go now!"
He then headed the project that designed and built the IBM S/360 series of mainframes. It was an audacious concept for the time—five different models, with vastly different prices and performance characteristics, but all sharing (essentially) the same instruction set. Furthermore, that instruction set was defined by the architecture, not by some accident of wiring. (Fun fact: the IBM 7094 (I think it was the 7094 and not the 7090) had a user-discovered "Store Zero" instruction. Some customers poked around and found it, and it worked. The engineers checked the wiring diagram and confirmed that it should, so IBM added it to the manual.) There were a fair number of interesting aspects to the architecture of the S/360, but Brooks felt that one of the most important contributions was the 8-bit byte (and hence the 32-bit word).
He went on to manage the team that developed OS/360. He (and Watson) regarded that as a failure; they both wondered why, since he had managed both. That’s what led him to write The Mythical Man-Month.
He left IBM because he felt that he was Called to start a CS department. This was an old desire of his; he always knew that he was going to teach some day. (Brooks was devoutly religious. Since I don’t share his beliefs, I can’t represent them properly and hence will say nothing more about them. I will note that in my experience at least, he respected other people’s sincere beliefs, even if he disagreed.)
I started grad school at Chapel Hill a few years later. Even though he was the department chair, with many demands on his time—he had a row of switch-controlled clocks in his office, so that he could track how much time he spent on teaching, research, adminstration, etc.—he taught a lot. I took four courses from him: software engineering (the manuscript for The Mythical Man-Month was our text!), computer architecture, seminar on professional practice, and seminar on teaching. I still rely on a lot of what I learned from him, lo these many years ago.
Late one spring, he asked me what my summer plans were. "Well, Dr. Brooks, I’d like to teach." (I’d never taught before but knew that I wanted to, and in that department in that time, PhD students had to teach a semester of introductory programming, with full classroom control. I ended up teaching it four times, because I really liked teaching.)
Brooks demurred: "Prof. X’s project is late and has deliverables due at the end of the summer; I need you to work on it."
"Dr. Brooks, you want to add manpower to a late project?" (If you’ve read The Mythical Man-Month, you know the reference—and if you haven’t read it yet, you should.)
He laughed, told me that this was a special case, and that I should do it and in the fall I could have whatever assistantship I wanted. And he was 100% correct: it was a special case, where his adage didn’t apply.
Brooks was dedicated to education and students. When it came to faculty hiring and promotion, he always sought graduate student input in an organized setting. He called those meetings SPQR, where the faculty was the Senate. In one case that I can think of, I suspect that student input seriously swayed and possibly changed the outcome.
He had great confidence in me, even at low points for me, and probably saved my career. At one in my odd grad school sojourn, I needed to take a year off. I had a faculty job offer from another college, but Brooks suspected, most likely correctly, that if I left, I’d never come back and finish my PhD. He arranged for me to be hired in my own department for a year—I went from PhD student to faculty member and back to student again. This was head-spinning, and I didn’t adapt well at first to my faculty status, especially in the way that I dressed. Brooks gently commented to me that it was obvious that I still thought of myself as a student. He was right, of course, so I upgraded my wardrobe and even wore a tie on days that I was teaching. (I continued to dress better on class days until the pandemic started. Maybe I’ll resume that practice some day…)
At Chapel Hill, he switched his attention to computer graphics and protein modeling. He’d acquired a surplus remote manipulator arm; the idea was that people could use it to "grab" atoms and move them, and feel the force feedback from the varying charge fields. From there, it was a fairly natural transition to some of the early work in VR.
Two more anecdotes and then I’ll close. Shortly after the department had gotten its first VAX computers, a professor who didn’t understand the difference between real memory and virtual memory fired up about 10 copies of a large program. The machine was thrashing so badly that no one could get anything done, including, of course, that professor. I was no longer an official sysadmin but I still had the root password. I sent a STOP signal to all but one copy of the program, then very nervously sent an email to that professor and Brooks. Brooks’ reply nicely illustrates his management philosophy: "if someone is entrusted with the root password, they have not just the right but the responsibility to use it when necessary."
My last major interaction with Brooks while I was a student was when I went to him to discuss two job offers, from IBM Research and Bell Labs (not Bell Labs Research; that came a few years later). He wouldn’t tell me which to pick; that wasn’t his style, though he hinted that Bell Labs might be better. But his advice is one I often repeat to my students: take a sheet of paper, divide it into two columns, and as objectively as you can list the pluses and minuses of each place. Then sleep on it and in the morning go with your gut feeling.
Frederick P. Brooks, Jr.: May his memory be for a blessing.
Attacker Target Selection
There’s a bit of a debate going on about whether the Kaseya attack exploited a 0-day vulnerability. While that’s an interesting question when discussing, say, patch management strategies, I think it’s less important to understanding attackers’ thinking than target selection. In a nutshell, when it comes to target selection, the attackers have outmaneuvered defenders for almost 30 years.
In early 1994, CERT announced that attackers were planting network eavesdropping tools—"sniffers"—on SunOS hosts, and were using these to collect passwords. What was known in the security community but not mentioned in the CERT advisory was how strategically these sniffers were placed: on major Ethernet segments run by ISPs. Back then, in the era before switched Ethernet was the norm, an Ethernet network was a single domain; every host could see every packet. That was great for network monitoring—and great for surreptitious eavesdropping. All security people understood both halves of that equation, but the attackers realized that backbone links offered far more opportunities to collect useful passwords than ordinary sites’ networks.
Fast-forward a decade to 2003, when the Sobig.f virus made its appearance. In the words of a retrospective look, "[Tt]he whole Sobig family was incredibly significant because that was the point where spam and viruses converged." Again, that hacked computers could be used for profit wasn’t a new idea, but few defenders realized until too late that the transition had taken place in the real world.
A few years later, credit card payment processors were hit, most famously Heartland Payment Systems. This is an industry segment most people didn’t realize existed—weren’t charges and payments simply handled by the banks? But the attackers knew, and went after such companies.
The current cast of malware operators are again ahead of the game, by going after cyber-infrastructure companies such as SolarWinds and Kaseya. This gives them leverage: go after one company; penetrate thousands. The payoff might be intelligence, as in the SolarWinds hack, or it might be financial, as with Kaseya. And the ransomware perpetrators are apparently being very strategic:
Cyber-liability insurance comes with a catch, however: It may make you more vulnerable to a ransomware attack. When cyber-criminals target cyber-insurance companies, they then have access to a list of their insured clients, which cyber-criminals can then use to their advantage to demand a ransom payment that mirrors the limit of a company’s coverage.Attackers even exploit timing:
DarkSide, which emerged last August, epitomized this new breed. It chose targets based on a careful financial analysis or information gleaned from corporate emails. For instance, it attacked one of Tantleff’s clients during a week when the hackers knew the company would be vulnerable because it was transitioning its files to the cloud and didn’t have clean backups.
The challenge for defenders is to identify what high-value targets might be next. A lot of defense is about protecting what we think are high-value systems, but we’re not always assessing value in the same way as the attackers do. What’s next?
Where Did "Data Shadow" Come From?
Anyone who works in privacy is familiar with the term "data shadow": the digital record created by our transactions, our travels, our online activities. But where did the phase come from? Who used it first?
A number of authors have attributed it to Alan Westin, whose seminal book Privacy and Freedom (largely a report on the work of the Committee on Science and Law of the Association of the Bar of the City of New York) set the stage for most modern discussions of privacy. I followed the lead of some other authors, e.g., Kevin Keenan’s 2005 book Invasion of Privacy: A Reference Handbook in saying that the phrase appeared in Privacy and Freedom. Simson Garfinkel’s 2000 book Database Nation is more circumspect, attributing it to Westin in the 1960s, but not citing a particular work. However, repeated searches of Westin’s works do not turn up that phrase.
Other authors point to different origins. Harvey Choldin says that the term is used by German sociologists, and cites an interview. Can we push it back further?
Google Scholar turned up a 1983 reference in Politics on a Microchip by Edwin Black. A Google Ngram search by Garfinkel shows nothing before 1976. But a more complete Google search turned up a 1974 usage by Kirstein Aner [sic] in New Scientist. They quote her as saying
Every single person will be closely followed all his life by his own data shadow where everything he has ever done, learnt, bought, achieved, or failed to achieve is expressed in binary numbers for eternity. His shadow will often be taken for himself and we will have to pay for all the inaccuracies as if they were his own; he will never know who is looking at is shadow or why.Kerstin Anér was a member of the Swedish legislature.
At that point, I asked a Swedish friend for help. He found some useful references to "dataskugga". Page 231 of Kretslopp Av Data says, via Google Translate:
By the term "data shadow" Kerstin Anér meant "the two-dimensional image of the individual that is evoked through one or more data registers" or "the series of crosses in different boxes that a living person is transformed into in the data registers and which tends by those in power to be treated as more real and more interesting than the living man himself.The footnote for the quote points to Anér’s 1975 book Datamakt (Computer Power) and says (again via Google Translate):
Anér referred to in the article [unsigned], “Data law must protect privacy. But we are still sold as issues ”, Dagens Nyheter, 13 July 1973; Ten years later, the term was still in use: Calle Hård, "The story of the data shadow 600412– 5890", Aftonbladet, 11 March 1982.
There was one more tantalizing reference. Google Books turned up a reference to "data shadow" in OECD Informatics with a possible date of 1971. When I finally obtained access to Volume 12, I found that it was from 1978—in an article by Anér.
That’s as far back as I’ve been able to trace it: Kerstin Anér, probably in 1972 or 1973. Does anyone have any earlier uses, in any language?
Acknowledgments: Patrik Fältström did the Swedish research. Tarah Wheeler and Matthew Nuding tracked down the OECD volume. Simson Garfinkel also did assorted web searches.
Vaccine Scheduling, APIs, and (Maybe) Vaccination Passports
As most Americans who have received a Covid-19 vaccination—or who have tried to schedule one—know, attempting to make an appointment is painful. Here is a thread describing the ordeal in Maryland, but it’s broadly similar elsewhere. In New York City, where I live, vaccines are administered by the city, the state, several different pharmacy chains, countless local pharmacies, some major medical centers, and more, and you have to sign up with each of them separately to see if any appointments are available. Here, the situation was so crazy that unofficial meta-sites have sprung up. The New York City Council passed a law requiring the city to create an official central web site.
It didn’t have to be this way, if proper planning and development had started last year, at the national level, but of course it didn’t. The answer is simple, at least conceptually: standardized interfaces, sometimes called APIs (application program interfaces) or network protocols.
Every large medical provider has its own scheduling system. These exist, they’re complex, they may be linked to patient records, staff availability, etc. That includes pharmacy chains—I had to use such a system to schedule my last flu shot. It isn’t reasonable to ask such organizations to replace their existing scheduling systems with a new one. That, however isn’t necessary. It is technically possible to design an API that a central city or county scheduling web page could implement. Every vaccination provider in the jurisdiction could use their half of the API to interface between their own scheduling systems and the central site. The central site could be designed to handle load, using well-understood cloud computing mechanisms. Indepdendent software vendors could develop scheduling packages for non-chain pharmacies that don’t have their own. It all could have been very simple for people who want to be vaccinated.
Mind you, designing such an API is not a trivial task. Think of all of the constraints that have to be communicated: age, job, residence, place of work, what eligibility categories a provider will accept, and more. There need to be mechanisms for both individuals to schedule shots for themselves or their families, and for operators of city-run phone banks to make appointments for the many people who don’t have computer access of their own, or who can’t cope with a web site that may have been poorly designed. You need logins, "I forgot my password", wait lists, people who can show on short notice lists, cancellation, queries, and more. Nevertheless, this is something that the tech industry knows how to do. (I used to be part of the leadership of the Internet Engineering Task Force, which standardizes many of the network protocols we all use. That’s why I, on a Mac, can send email via a Linux web server to a Windows user, which they may view using a platform-independent web browser: there are standardized ways to do these things. Protocols can be simple or complex, but they’re routinely designed.)
And once you have an API, software developers have to implement it, for central sites, for small providers, and as interfaces to existing scheduling systems. That latter is itself likely to be a complex task, since you’re touching a large, probably messy codebase. Nevertheless, this is all routine in the software business.
All of this could have been done. It should have been done; the situation—high demand for a limited resource, with various priority levels—was predictable long ago. As soon as it was apparent that the world was confronting a deadly pandemic that could be dealt with by a vaccine—that SARS-CoV-2 had that spreading potential was understood by some in January 2020, and Moderna had its vaccine designed two days after they received the virus’ genome sequence—the Department of Health and Human Services should have convened an API design group. In parallel with that, developers could have started on their own software while waiting for the API specs to be finalized. I’ll take it a step further: we should still go ahead with this effort. We may need it for booster shots or to cope with new variants; we’ll certainly need it for the next pandemic.
And we may need something similar now for vaccination passports. There is not yet a consensus on their desirability; that said, many places already require them. Almost certainly, the little card you got from your provider is inadequate in the long run. You’ll have to request the standardized version, either on paper or for the many different apps you’ll likely need—and that many need a similar API.
Security Priorities
In the wake of recent high-profile security incidents, I started wondering: what, generally speaking, should an organization’s security priorities be? That is, given a finite budget—and everyone’s budget is finite—what should you do first? More precisely, what security practices or features will give you the most protection per zorkmid? I suggested two of my own, and then asked my infosec-heavy Twitter feed for suggestions.
I do note that I’m not claiming that these are easy; indeed, many are quite hard. Nevertheless, they’re important.
I started with my own top choices.
- Install patches
- Few organizations are hit by zero-days. That doesn’t mean it can’t happen, and of course if you’re the target of a major intelligence agency the odds go up, but generally speaking, zero-days are far from the highest risk. Installing security patches promptly is a good defense.
- Use 2FA
- Good two-factor authentication—that often means
FIDO2—is basically a necessity for access from the outside.
Ordinary passwords can be phished, captured by keystroke
loggers, guessed, and more. While there are many forms of
2FA, FIDO2 ties the session to the far side’s identity,
providing very strong protection against assorted attacks.
This is harder to pull off internally—some form of single sign-on is a necessity; no one wants to type their password and insert their security key every time they need to open a file that lives on a server.
The next suggestion is one I should have thought of but didn’t; that said, I wholeheartedly agree with it.
- Inventory
- Know what computers you have, and what software they run. If you don’t know what you’ve got (and who owns it), you don’t know whom to alert when a security vulnerability pops up. Consider, for example, this new hole in VMware. Do you know how many VMware servers you have? If you ran the corporate security group and saw that alert, could you rapidly notify all of the responsible system administrators? Could you easily track which servers were upgraded, and when?
The next set of answers have to do with recovery: assume that you will suffer some penetration. Now what?
- Backups
- Have good backups, and make sure that at least one
current-enough set is offline, as protection against
ransomware.
I would add: test recovery. I’ve seen far too many situations where backups were, for some reason, incorrect or unusable. If you don’t try them out, you have no reason to think that your backups are actually useful for anything.
- Logging
- If you don’t have good logs, you won’t know what
happened. You may not even know if anything
has happened.
What should you log? As much as you can—disk space is cheap. Keep logs on a locked-won log server, and not on a machine that might otherwise be targeted. Logs from network elements, such as switches and routers (hint: Netflow), are especially valuable; ditto DNS logs. These show who has connected where, invaluable if you’re trying to trace the path of an intruder.
- Segmentation
- Your internal network should be segmented. The initial
point of entry of an attacker is probably not
their actual goal, which implies the need for lateral
movement. Internal segmentation is a way to hinder
and perhaps detect such movements.
Note that segmentation is not just firewalls, though those are probably necessary. You should also have separate authentication domains. Look at what happened to Maersk in the NotPetya attack:
Maersk’s 150 or so domain controllers were programmed to sync their data with one another, so that, in theory, any of them could function as a backup for all the others. But that decentralized backup strategy hadn’t accounted for one scenario: where every domain controller is wiped simultaneously. “If we can’t recover our domain controllers,” a Maersk IT staffer remembers thinking, “we can’t recover anything.”
After a frantic search that entailed calling hundreds of IT admins in data centers around the world, Maersk’s desperate administrators finally found one lone surviving domain controller in a remote office—in Ghana. At some point before NotPetya struck, a blackout had knocked the Ghanaian machine offline, and the computer remained disconnected from the network. It thus contained the singular known copy of the company’s domain controller data left untouched by the malware—all thanks to a power outage. “There were a lot of joyous whoops in the office when we found it,” a Maersk administrator says.
- Intrusion detection
- Monitor for attacks. There have been far too many cases—think Sony and Equifax—where the attackers were inside for quite a while, exfiltrated a lot of data, and weren’t detected. Why not? Note that your logs are a very useful source of information here—if you actually have the tools to look at them automatically and frequently.
- Harden machines for outside life
- That is, assume that some machines are going to be
seriously attacked as if it were on the open
Internet. I’m not saying you shouldn’t have
a firewall, but again, assume lateral movement
by an adversary who has already gotten past that
barrier.
This isn’t easy, even by the standards I’ve set by warning that some of these things are hard. Do you encrypt all internal links? It’s a good idea, but imposes a lot of operational overhead, e.g., renewing certificates constantly.
- Red-team external software
- If you have the resources—and few small or medium organizations do—have a group that does nothing but bang on software before it’s deployed. Fuzz it, monitor it, and more, and see what breaks and what attempts are logged. Note that this is not the same as penetration-testing a company—that latter is testing how things are put together, rather than the individual pieces.
Some suggestions I can’t endorse wholeheartedly, even though in the abstract they’re good ideas.
- User education
- I’m all in favor of teaching people about the bad things that can happen, and in my experience you get a lot more cooperation from your user communityu when they know what the issues are. Don’t waste your time on rote rules ("pick strong passwords, with at least three upper-case letters, two heiroglyphics, at least one symbol from a non-human language, and a character from an ancient Etruscan novel"), or on meaningless, non-actionable tropes ("don’t click on suspicious links"). And don’t blame users for what are actually software failures—in an ideal world, there would be no risk in opening arbitrary attachments or visiting "dangerous" web sites.
- Proper, centralized access control
- If only—but the central security group has no idea who is really supposed to have permissions on every last server that’s part of a partnership with an external party.
Note how much of this requires good system administration and good management. If management won’t support necessary security measures, you’ll lose. And a proper sysadmin group, with enough budget and clout, is at the heart of everything.
I do want to thank everyone who contributed ideas, though of course many ideas where suggested by multiple people. The full Twitter thread is here.
Covid-19 Vaccinations, Certificates, and Privacy
Back when the world and I were young and I took my first international trip, I was told that I needed to obtain and carry an International Certificate of Vaccination (ICV).

With a bit of luck, we’ll have a vaccine soon for Covid-19. It strikes me as quite likely that soon after general availability, many countries will require proof of vaccination before you can enter, a requirement that might especially apply to Americans, given the disease rates here. But there’s a problem: how will border guards know if the certificate is genuine?
This is a very odd time in the U.S. Far too many people think that the disease is a hoax, and resist requirements to wear masks. More seriously, there are fraudulent "Freedom to Breathe Agency" cards that purport to exempt the bearer from mask-wearing requirements. It does not take any particular stretch of the imagination to suspect that we’ll see an outbreak of fake ICVs.
The obvious answer is some sort of unforgeable digital credential. Should this be a separate government-run database? More precisely, there would be many of them, run by governments around the world. Should WHO run it? How do these databases get populated? Are they linked to folks’ electronic health records? Employers and schools are likely to want similar verification—but how much of a person’s medical records should they have access to? (My university is going to require flu shots for all students.)
There are a lot of ways to get this wrong, including not doing anything to ensure that such certificates are genuine. But there are also risks if it’s done incorrectly. Are people working on this issue?
Hot Take on the Twitter Hack
If you read this blog, you’ve probably heard by now about the massive Twitter hack. Briefly, many high-profile accounts were taken over and used to tweet scam requests to send Bitcoins to a particular wallet, with the promise of double your money back. Because some of the parties hit are sophisticated and security-aware, it seems unlikely that the attack was a straightforward one directly on these accounts. Speculation is that a Twitter administrative account was compromised, and that this was used to do the damage.
The notion is plausible. In fact, that’s exactly what happened in 2009. The result was a consent decree with the Federal Trade Commission. If that’s what has happened again, I’m sure that the FTC will investigate.
Again, though, at this point I do not know what happened. As I’ve written, it’s important that the community learn exactly what happened. Twitter is a sophisticated company; was the attack good enough to evade their defenses? Or did they simply drop their guard?
Jack Dorsey, the CEO of Twitter, tweeted
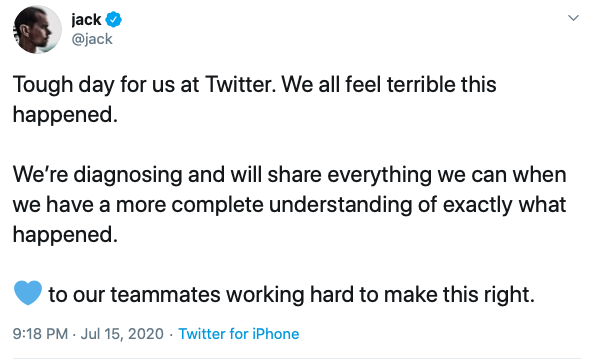
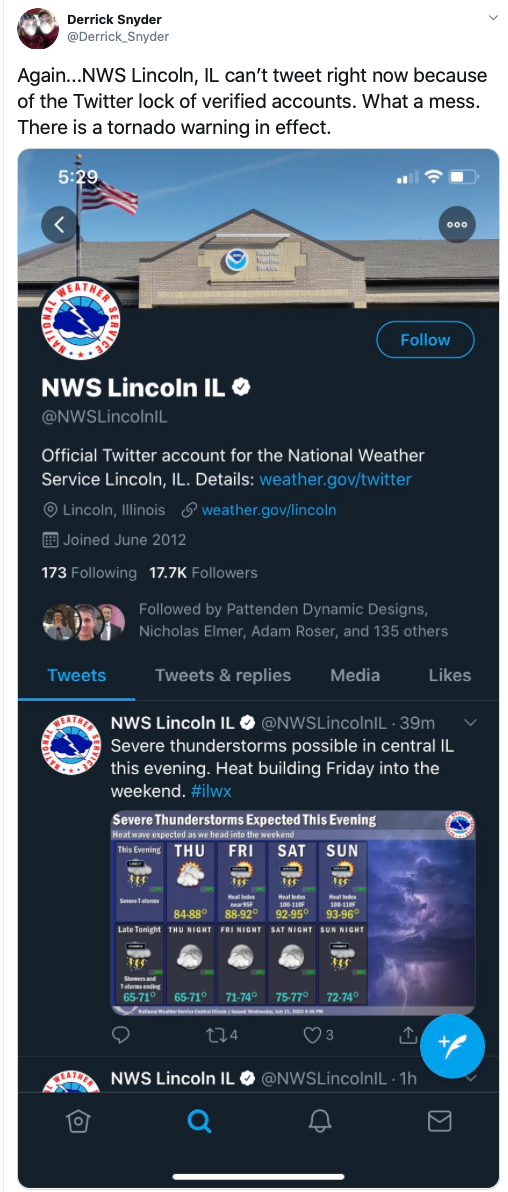
Twitter has become a crucial piece of the communications infrastructure; it’s even used for things like tornado alerts.
Trust Binding
A few months ago, there was a lot of discussion that despite its claims, Zoom did not actually offer end-to-end encryption. They’re in the process of fixing that, which is good, but that raises a deeper question: why trust their code? (To get ahead of myself, this blog post is not about Zoom.)
In April, I wrote
As shown by Citizen Lab, Zoom’s code does not meet that definition:If Zoom has the key but doesn’t abuse it, there isn’t a problem, right?
By default, all participants’ audio and video in a Zoom meeting appears to be encrypted and decrypted with a single AES-128 key shared amongst the participants. The AES key appears to be generated and distributed to the meeting’s participants by Zoom servers.Zoom has the key, and could in principle retain it and use it to decrypt conversations. They say they do not do so, which is good, but this clearly does not meet the definition [emphasis added]: no third party, even the party providing the communication service, has knowledge of the encryption keys.”
Let’s fast-forward to when they deploy true end-to-end encryption. Why do we trust their code not to leak the secret key? More precisely, what is the difference between the two scenarios? If they’re honest and competent, the central site won’t leak the key in today’s setup, nor will the end systems in tomorrow’s. If they’re not, either scenario is problematic. What is the difference? True end-to-end feels more secure, but why?
Let’s look at another scenario: encrypted email via a web browser. I’ll posit two implementations. In the first, the web site serves up custom JavaScript to do the decryption; in the second, there’s a browser plug-in that does the exact same thing. Again, the second version feels more secure, but why?
The answer, I think, is illustrated by the Lavabit saga:
The federal agents then claimed that their court order required me to surrender my company’s private encryption keys, and I balked. What they said they needed were customer passwords – which were sent securely – so that they could access the plain-text versions of messages from customers using my company’s encrypted storage feature.(Btw, Edward Snowden was the target of the investigation.) Lavabit was a service that was secure—until one day, it wasn’t. Its security properties had changed.
I call this the "trust binding" problem. That is, at a certain point, you decide whether to trust something. In the the two scenarios I described at the start, the trust decision has to be made every time you interact with the service. Maybe today, the provider is honest and competent; tomorrow, it might not be, whether due to negligence or compulsion by some government. By contrast, when the essential security properties are implemented by code that you download once, you only have to make your decision once—and if you were right to trust the provider, you will not suddenly be in trouble if they later turn incompetent or dishonest, or are compelled by a government to act against your interests.
Put another way, a static situation is easier to evaluate than a dynamic one. If a system was secure, it will remain secure, and you don’t have to revisit your analysis.
Of course, it cuts both ways: systems are often insecure or otherwise buggy as shipped, and it’s easier for the vendor to fix things in a dynamic environment. Furthermore, if you ever install patches for a static environment you have to make the trust decision again. It’s the same as with the dynamic options, albeit with far fewer decisions.
Which is better, then? If the vendor is trustworthy and you don’t face a serious enemy, dynamic environments are often better: bugs get fixed faster. That’s why Google pushes updates to Chromebooks and why Microsoft pushes updates to consumer versions of Windows 10. But if you’re unsure—well, static situations are easier to analyze. Just be sure to get your analysis right.
Facebook, Abuse, and Metadata
Last year, I wondered if Facebook was going to use metadata to detect possible misbehavior online. We now know that the answer is yes. Read the full article for details, but briefly, they’re using (of course) machine learning and features like message time, communication patterns compared with the social graph, etc. To give just one example, they can look for “an adult sending messages or friend requests to a large number of minors” as a possible sign of a pedophile.
Some of the effort is education: “Our new safety notices also help educate people on ways to spot scams or imposters and help them take action to prevent a costly interaction.” I have grave doubts that that will work well, but we’ll see.
The hard part is going to be knowing how well it works. How will they know about false positives, situations where they flag a communication as suspect but it really isn’t? For that matter, how will they know about true positives? I can think of possible answers, but I’ll wait for further details.
