FaceTracer: A Search Engine for Large Collections of Images with Faces |
 | |
The ability of current search engines to find images based on facial
appearance is limited to images with text annotations. Yet, there are many
problems with annotation-based search of images: the manual labeling of images
is time-consuming; the annotations are often incorrect or misleading, as they
may refer to other content on a webpage; and finally, the vast majority of
images are simply not annotated.
We have created the first face search engine, allowing users to
search through large collections of images which have been automatically
labeled based on the appearance of the faces within them. Our system lets
users search on the basis of a variety of facial attributes using natural
language queries such as, "men with mustaches," or "young blonde women," or
even, "indoor photos of smiling children." This face search engine can be
directed at all images on the internet, tailored toward specific image
collections such as those used by law enforcement or online social networks, or
even focused on personal photo libraries.
Like much of the work in content-based image retrieval, the power of our
approach comes from automatically labeling images off-line on the basis of a
large number of attributes. At search time, only these labels need to be
queried, resulting in almost instantaneous searches. Furthermore, it is easy
to add new images and face attributes to our search engine, allowing for future
scalability. Defining new attributes and manually labeling faces to match
those attributes can also be done collaboratively by a community of
users.
Our search engine owes its superior performance to two main factors:
A large and diverse dataset of face images with a significant subset
containing attribute labels. We currently have over 3.1 million aligned
faces in our database -- the largest such collection in the world. In addition
to its size, our database is also noteworthy for being a completely
"real-world" dataset, encompassing a wide range of pose, illumination, imaging
conditions, and captured using a large variety of cameras. Faces have been
automatically extracted and aligned using the Omron face and fiducial point
detector. In addition, 10 attributes have been manually labeled on more
than 17,000 of the face images, creating a large dataset for training and
testing classification algorithms. Our dataset is similar in spirit to the Labeled Faces in the Wild
dataset.
A subset of this dataset has been made publicly available. See below.
- A scalable and fully automatic architecture for attribute
classification. We present a novel approach tailored toward face
classification problems, which uses a boosted set of Support Vector Machines
(SVMs) to automatically select the best features for a given attribute. These
are used to then train a strong SVM classifier with high accuracy. A key aspect
of this work is that classifiers for new attributes can be trained
automatically, requiring only a set of labeled examples. Yet, the flexibility
of our framework does not come at the cost of reduced accuracy -- we compare
against several state-of-the-art classification methods and show the superior
classification rates produced by our system.
This work was supported by ONR Muri Award No. N00014-08-1-0638 and NSF grants IIS-03-08185 and ITR-03-25867. |
Publications
"FaceTracer: A Search Engine for Large Collections of Images with Faces,"
N. Kumar, P. N. Belhumeur, and S. K. Nayar,
European Conference on Computer Vision (ECCV),
pp. 340-353, Oct. 2008.
[PDF] [bib] [©] [Project Page]
|
Images
 |
|
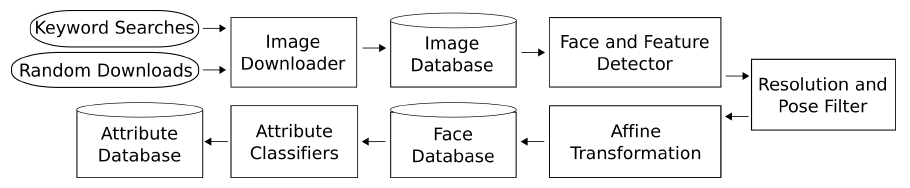
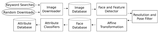
Overview of the Database Creation Process:
Images are first downloaded from the internet and run through a face and
fiducial point detector to extract the faces within them. These faces are
filtered for quality and affine-transformed to a common coordinate system, and
then run through a set of attribute classifiers to obtain attribute labels,
which are stored in the attribute database. At search time, only this attribute
database needs to be searched, resulting in real-time searches.
|
| |
|
|
 |
|
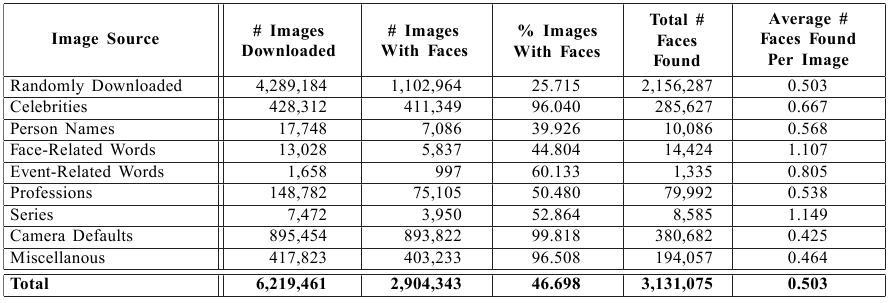
Image Database Statistics:
We have collected what we believe to be the largest set of aligned real-world
face images (over 3.1 million so far). These images have been downloaded from
the internet, and exhibit a large amount of variation -- they are in completely
uncontrolled lighting and environments, taken using unknown cameras and in
unknown imaging conditions, with a wide range of image resolutions. Notice that
more than 45% of the downloaded images contain faces, and on average, there is
one face per two images.
|
| |
|
|
 |
|
List of Labeled Attributes:
We have manually labeled over 17,000 attributes in our face database. These
labels are used for training our classifiers, allowing for automatic
classification of the remaining faces in our database. Note that these were
labeled by a large set of people, and thus the labels reflect a group consensus
about each attribute rather than a single user's strict definition.
|
| |
|
|
 |
|
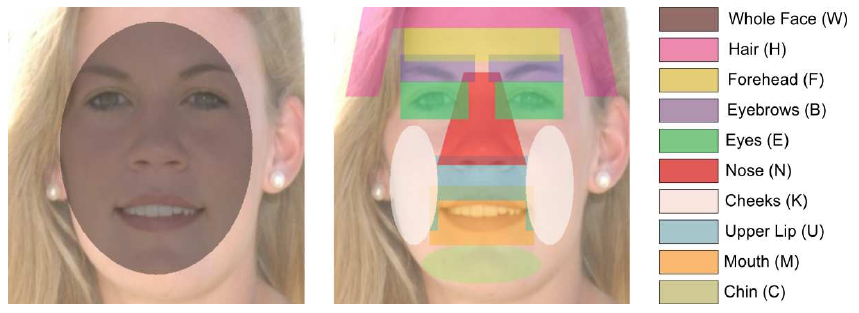
Face Regions used for Automatic Feature Selection:
Our feature selection process automatically selects features from our set of
10 regions. On the left is one region corresponding to the whole face, and on
the right are the remaining regions, each corresponding to functional parts of
the face. The regions are large enough to be robust against small differences
between individual faces and overlap slightly so that small errors in alignment
do not cause a feature to go outside of its region. The letters in parentheses
denote the code letter for the region, used as a shorthand notation for
describing particular feature combinations.
|
| |
|
|
 |
|
Feature Type Options:
Our feature selection process automatically selects one or more feature types
from these options. A complete feature type is constructed by first converting
the pixels in a given region to one of the pixel value types from the first
column, then applying one of the normalizations from the second column, and
finally aggregating these values into the output feature vector using one of
the options from the last column. The letters in parentheses are used as code
letters in a shorthand notation for concisely designating feature types.
|
| |
|
|
 |
|
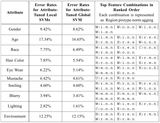
Results of our Training Algorithm:
This table shows error rates obtained by our training algorithm. In most
cases, our error rates are under 10%. The top feature combinations selected by
our algorithm are shown in the last column, in ranked order from more important
to less as ``Region:feature type'' pairs, where the region and feature types
are listed using the code letters defined above. For example, the first
combination for the hair color classifier, ``H:r.n.s,'' takes from the hair
region (H) the RGB values (r) with no normalization (n) and using only the
statistics (s) of these values.
|
| |
|
|
 |
|
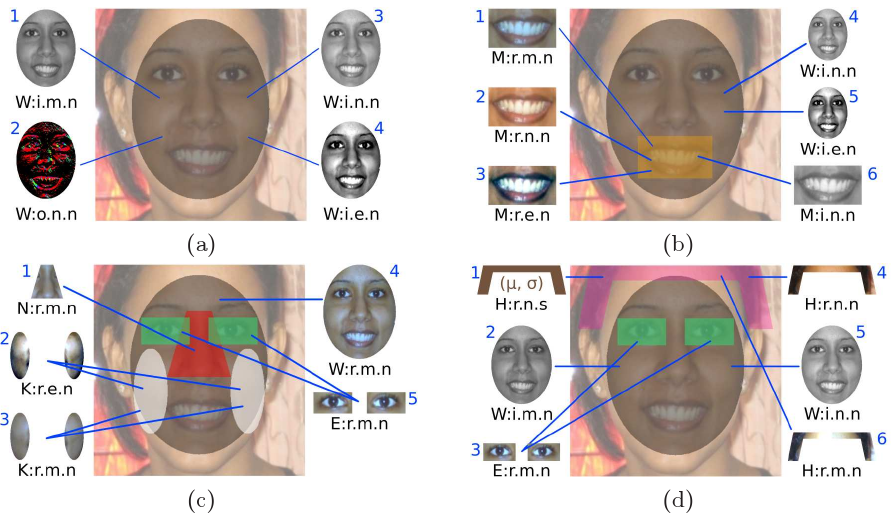
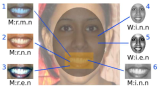
Illustrations of Automatically-Selected Feature Combinations:
The images show the top-ranked feature combinations for (a) gender, (b)
smiling, (c) environment, and (d) hair color. These feature combinations were
automatically selected by our training algorithm. Notice how each classifier
uses different regions and feature types of the face. It would be impossible to
define all of these manually for each attribute and maintain our high
accuracies.
|
| |
|
|
 |
|
Comparison of Classification Performance against Prior Methods:
Our
attribute-tuned global SVM performs better than prior state-of-the-art methods.
Note the complementary performances of both Adaboost methods versus the
full-face SVM method for the different attributes, showing the strengths and
weaknesses of each approach. By exploiting the advantages of each, our approach
achieves the best performance.
|
| |
|
|
 |
|
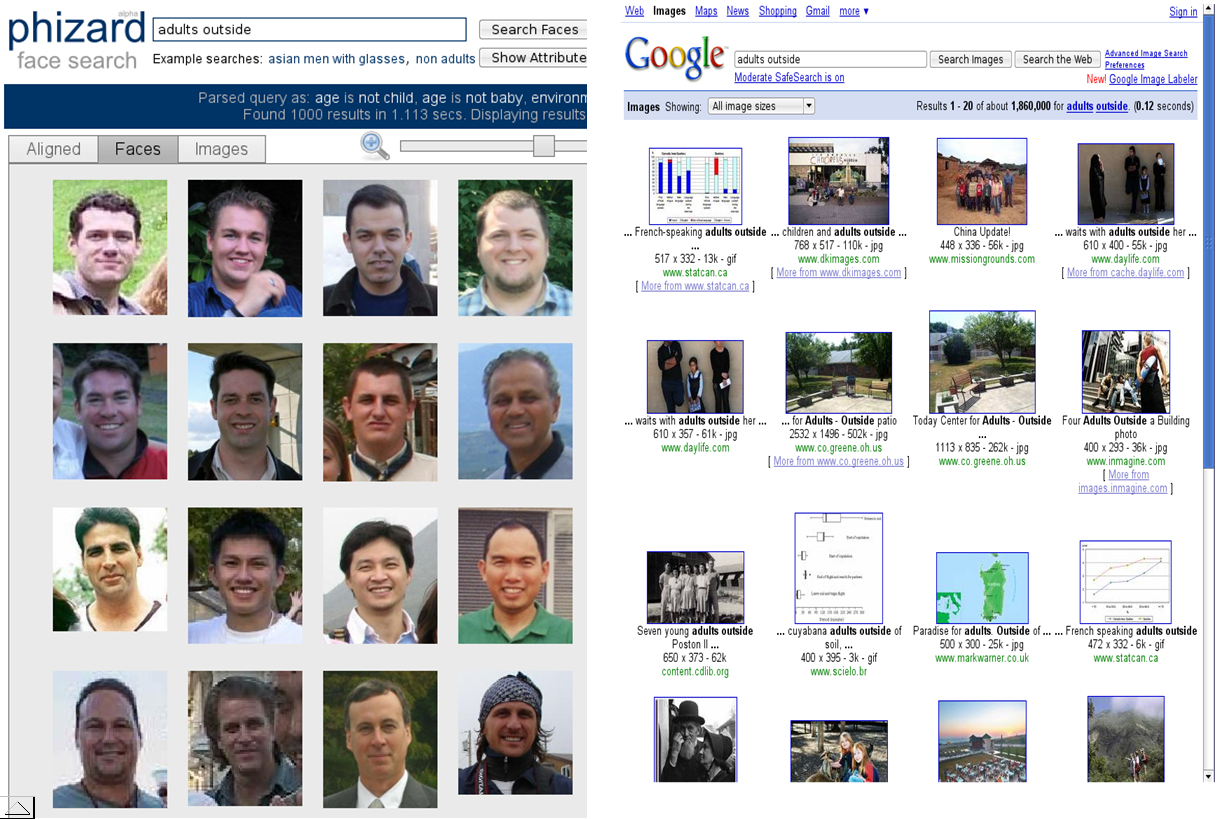
Results for Query "Adults Outside":
Comparison of results for the query
"adults outside" using our search engine (left) and Google image search (right). Notice that
since Google is dependent on text labels for searching through images, many of
their results have no relevance to the query. In contrast, our search engine
finds good results because our system has labeled each face using our attribute
classifiers (offline).
|
| |
|
|
 |
|
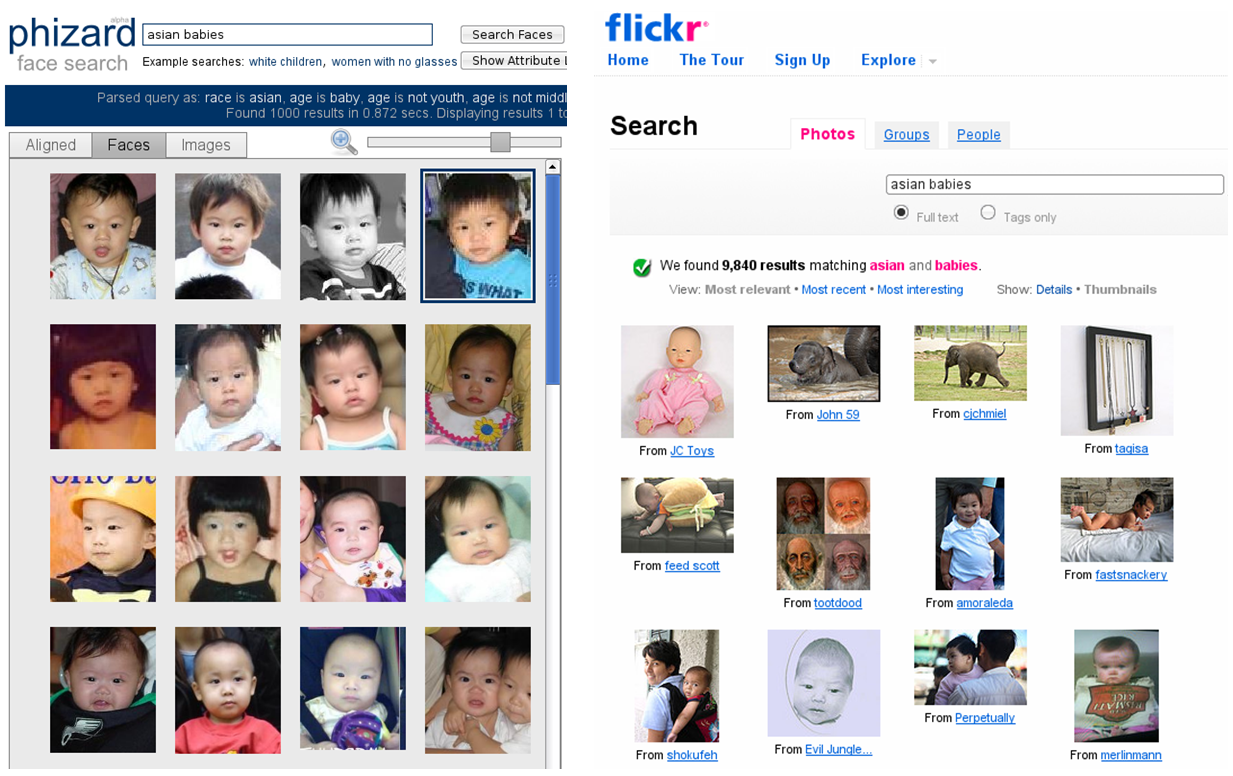
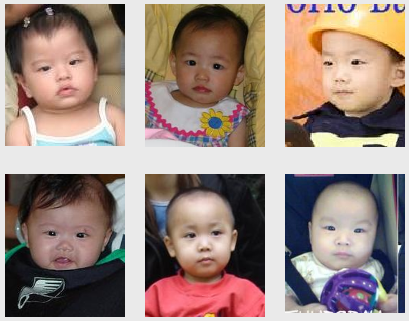
Results for Query "Asian Babies":
Comparison of results for the query "asian babies" using our search engine
(left) and Flickr (right). Flickr allows users
to search using manually annotated image "tags." However, because it is tedious
to tag each image, users often tag entire photosets with the same tags,
resulting in many incorrect tags for individual images. Thus, search results
often contain many wrong results. Furthermore, the vast majority of images on
flickr are simply not tagged, making them "invisible" to search.
|
| |
|
|
 |
|
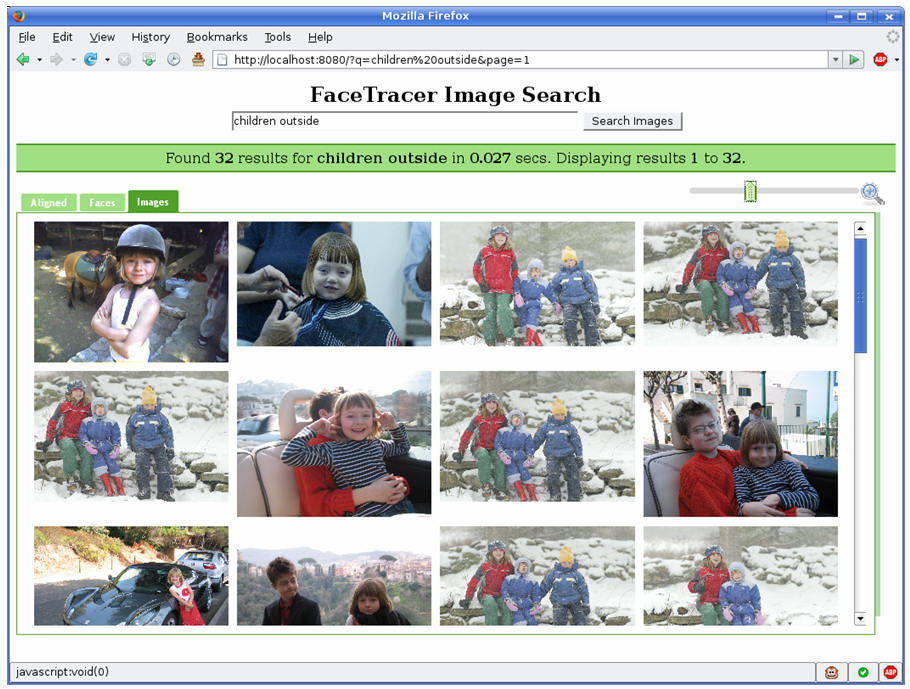
Results for Query "Children Outside" using a Personalized Image Search:
Our
search engine can also be applied to a user's own set of photos, allowing for
personalized image searches. In this way, one can quickly locate specific
images of friends or family members. Thus, our search engine can be a useful
addition to existing personal photo management software by allowing people to
easily organize their photos on the basis of the faces within them.
Furthermore, one could also search for (and remove) bad quality images, or even
train his own classifiers.
|
| |
|
|
|
Video
 |
|
ECCV 2008 Video:
This video introduces our face search engine. It describes the database
creation process and shows several example queries. (With narration)
|
| |
|
|
|
Slides
ECCV 2008 presentation
|
Database
 |
|
FaceTracer Database:
We have made a large portion of our database publicly available for use by vision researchers. This dataset includes a several thousand detected faces, locations of fiducial points, links to the original webpages on which the images were found, and also a significant number of manually labeled attributes.
|
| |
|
|
|
Attribute and Simile Classifiers for Face Verification
Appearance Matching
Face Swapping: Automatically Replacing Faces in Photographs
Labeled Faces in the Wild (UMass Project)
|
|
|