
Resource reservation must accommodate the rapid growth and
increasing service diversity of the Internet. Recently, hierarchical
architectures have been proposed that provide domain-level reservation.
However, it is not clear that these proposals [Jacobson,
Guerin, Boomerang,
UCLA], can set up and maintain
reservations in an efficient and scalable fashion.
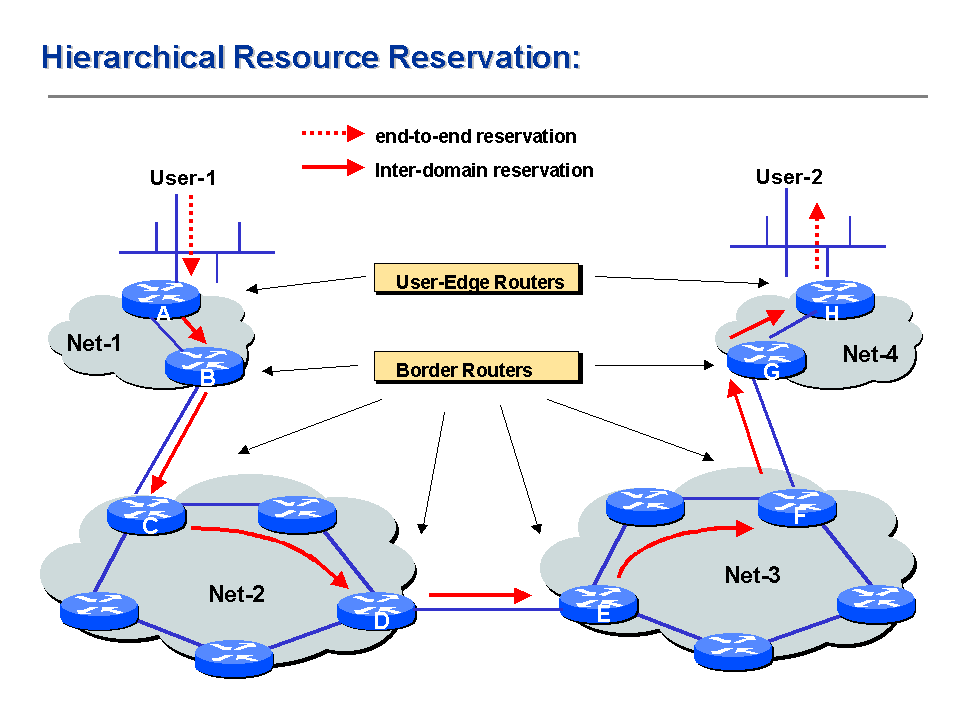
In this work, we describe a distributed architecture for inter-domain aggregated resource reservation
for unicast traffic. We also present an associated protocol, called the Border Gateway Reservation Protocol (BGRP),
that scales well, in terms of message processing load, state storage and bandwidth. Each stub or transit
domain may use its own intra-domain resource reservation
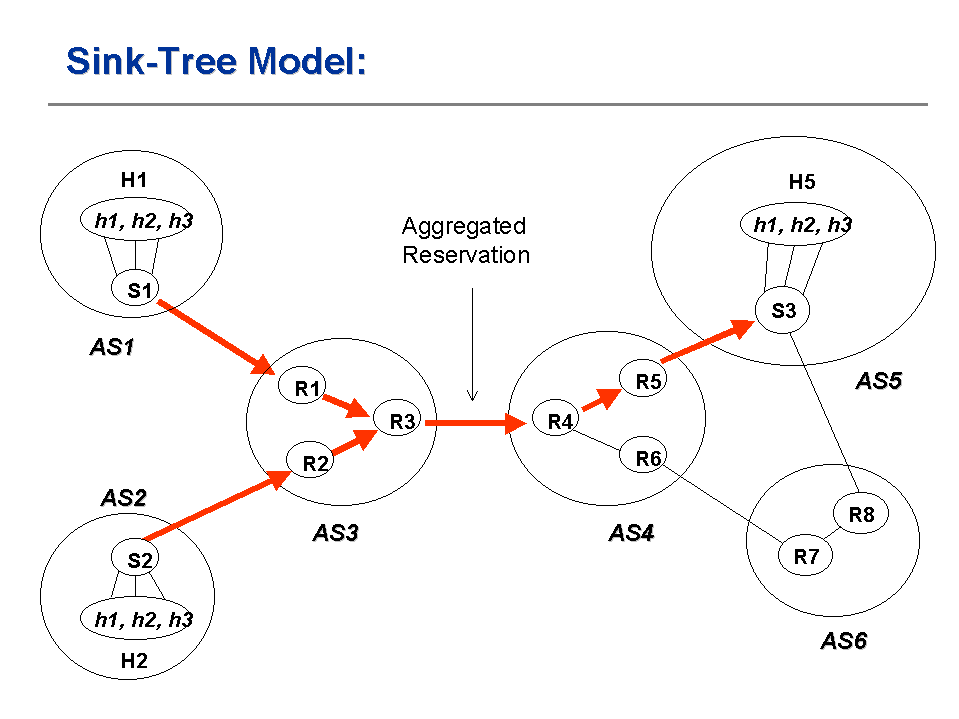
protocol. BGRP builds a sink tree for each of the stub
domains. Each sink tree
aggregates bandwidth reservations from all data sources in the network. Since backbone routers only maintain the sink tree information, the
total number of reservations at each router scales linearly with the number of Internet domains
N. (Even aggregated versions of the current protocol RSVP have an overhead that grows like
N2.)
BGRP relies on Differentiated Services for data forwarding. As a result, the number of packet classifier entries is extremely small. To reduce the protocol message traffic, routers may reserve domain bandwidth beyond the current load, so that sources can join or leave the tree or change their reservation without having to send messages all the way to the tree root for every such change. We use ``soft state'' to maintain reservations. In contrast to RSVP, refresh messages are delivered reliably, allowing us to reduce the refresh frequency.
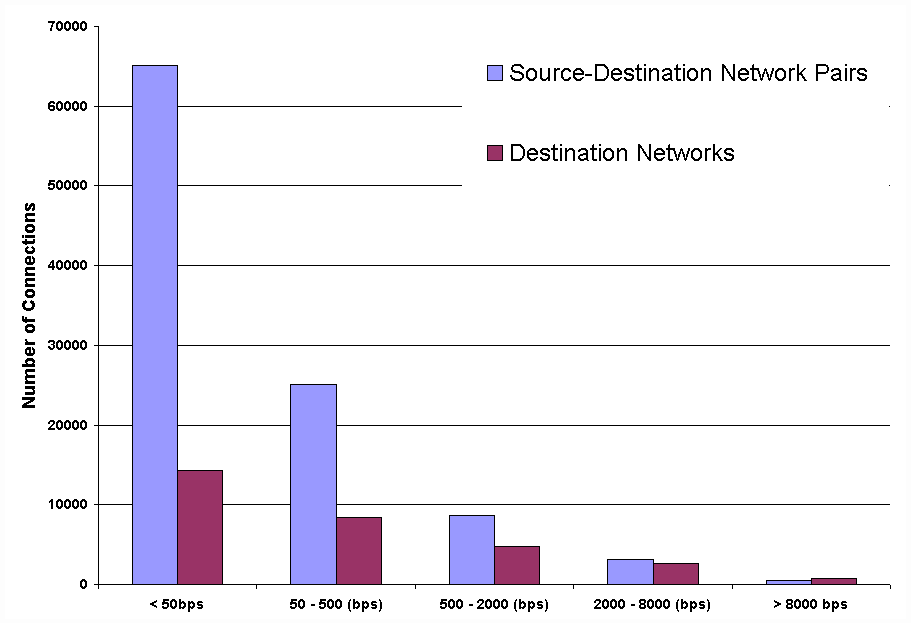
Since resource reservation is not yet widely used, we have to extrapolate the likely volume of reservation state from other observations. To that end, we collected a 90-second traffic trace from the MAE-West network access point (NAP). We categorized about 3 million IP packet headers from June 1, 1999, according to their transport-layer port, IP address, IP network prefix and BGP Autonomous System (AS). Here is the result:
| Granularity | Flow discriminators | Flows |
| Application | source address and port | 143,243 |
| destination address and port, protocol type | 208,559 | |
| 5-tuple | 339,245 | |
| IP Host | source address | 56,935 |
| destination address | 40,538 | |
| source-destination pairs | 131,009 | |
| Network (Class A/B/C) | source network | 13,917 |
| destination network | 20,887 | |
| source-destination pairs | 79,786 | |
| AS | source AS | 2,244 |
| destination AS | 2,891 | |
| source-destination pairs | 20,857 |
For example, if we use RSVP and
its
extensions, the total number of reservations can range from 20,857 if we reserve source-destination AS
pairs up to 339,245 if every flow identified by a unique 5-tuple gets its own reservation.
Can network routers handle hundreds of thousands of reservations? After all, telephone switches handle tens of thousands of simultaneous calls.
In a recent study, we showed that a low-end router can set up 900 new RSVP reservations or maintain up to 1600 reservations
per second, allowing it to sustain about 45,000 flows. To sustain that rate, the router has to suspend routing computation and packet
forwarding due to its hardware and CPU constraints. While backbone routers have more CPU power than the low-end router used for the
measurements, other results
indicate that
frequent routing computation due to route instability may already tax the CPU. Thus, we, along with some RSVP developers we talked to,
believe that in many networking environments, routers do not have enough CPU power to sustain hundreds of thousands of reservations.
From the table, we observe that there are about 21,000 unique source-destination AS pairs, which a backbone router should be able to
handle. However, this number is artificially low due to the small 90-second window. Over the span of a month (May 1999),
MAE-West saw 4,908 unique source AS's, 5,001 unique destination AS's and 7,900,362 unique AS pairs, out of the 25 million possible
combinations. Thus, unless edge routers tear down AS-level trunks frequently, there may be too many AS-level ``trunks'' to sustain in backbone routers.
It has been argued that since network link bandwidth is finite, it is unlikely that a link would see thousands of reservations. On the one
hand, if we assume that a voice call is the finest granularity of reservation, an OC-192 link carrying 16 kb/s voice flows could support
up to 600,000 such calls. On the other hand, our traces indicate that
the MAE-West link carries only several hundred high-volume flows. The latter seems to lead to a conclusion that reserving resources for high-volume flows does not pose scaling problems.
However, some of the recent IETF activities on
MPLS and Traffic
Engineering have suggested using the reservation signaling protocols to set up VPN trunks
and to provide service differentiation among users. The reservations can be in the forms of traffic class, bandwidth as well as label.
We thus envision that it is quite possible to have many reserving flows or LSP's on a given link in the backbone.
The table also indicates that the number of source and destination AS's and networks is relatively small.
Bates' statistics
show that there were approximately 5,000 autonomous systems and fewer than 60,000 network prefixes in the Internet in June 1999. Hence, if we
set up reservations based on either source or destination AS's or network prefixes, we can readily keep the reservation count at levels
sustainable by today's routers.
In networks where the shortest paths are unique, Bellman's principle of optimality guarantees that routes
to any destination form a tree, and routes from any source also form a
tree. In today's Internet, all unicast routing algorithms, including
OSPF, RIP and BGP, define sink-based trees, one for each destination. BGP
establishes ``virtual edges'' by using reachability as a definition for the existence of a link in the graph. In case of paths of equal weight,
current BGP practice dictates that the router forward all packets over only one path. This practice guarantees that routing always follow sink
trees. If reservations are make along routes chosen by the routing algorithms, it is natural to aggregate these reservations along the sink
trees formed by routing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}