|
A
Simple Approach to Genetic Programming Cost Minimization.
|
|
Paolo
de Dios and Stephen Jan
Columbia University, w4771 Machine Learning {pd119, sj178}@columbia.edu |
| Abstract |
| Determining
the right hypothesis representation is a difficult task. Perhaps the hardest
part of deriving the proper hypothesis, especially in genetic programming
applications is determining whether or not the proper attributes are properly
represented. The accuracy of this hypothesis representation directly affects
the computation time and effectiveness of genetic programs. In this experiment, we attempt to utilize human derived strategies in order to properly represent the attributes necessary to derive a hypothesis reprsentation that can be more quicly generated. The goal of this experiment is to test one method for increasing the learning rate and reducing the computation time in genetic programming applications. This technique is geared towards the game Othello. |
| Introduction and Motivation |
| Genetic programming
is an effective, but costly learning method that optimizes a problem solution
by simulating biological evolution. It performs program or hypothesis evolution
via a series of crossovers and mutations on a "population" of function trees
that reprsent various configurations of the hypothesis. Candidates for "genetic
propagation" are selected through probabilistic, tournament, randomized
or greedy selection algorithms according to some fitness measure. These genetic algorithms model evolution well. They attempt to probabilistically produce a diverse function population. The problem with these methods is that that they are computationally intensive applications. In order to produce succesively optimized hypothesis representations, genetic algorithms must be able to produce fit individuals that meet or exceed a certain watermark for for performance. Since these function trees are probabilistically selected, the performance of the resulting function trees can vary every generation. They may or may not meet the fitness criteria for selection, thus protracting the evolution process in order find a set of fit individuals for the next generation. There are a number of ways to approach this problem. An obvious method would be to change the genetic algorithm itself to be less computationally intensive. The difficulty of that approach is that it may require mathematical rigor to find an alternative method that can accurately model biological evolution. Another method is to modify or select a less stringent fitness criteria. Once again, this method is difficult to model because it is dificult to model how well a certain function tree is going to perform at a given fitness level. It may very well require great amounts of testing and tweaking to get just right. In the interest of time and cpu resources, we have opted to go with a simpler approach. We decided to optimize the hypothesis represntation by examining human learning performance against EDGAR in Othello. The idea is that since humans are faster learners than computers, it would be better to use humans to assist in deriving a more accurate hypothesis representation to help get the genetic programming system off to a good start. The hope is that either a smaller or more accurate hypothesis representation would translate to better performance. A smaller hypothesis space would reduce the time it takes to generate function populations. A more accurate representation would increase the performance against Edgar. |
| Experimental Setup | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| Results | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Conclusion |
| As one can see,
there is no obvious trend of improved performance for a human agent, the
performance of a person fluctuates. The performance seems extremely erratic.
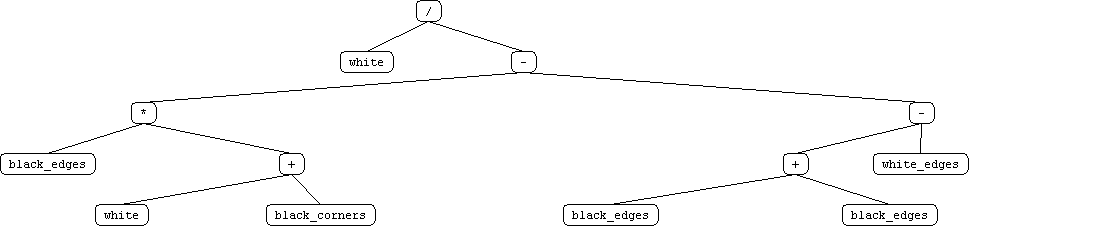
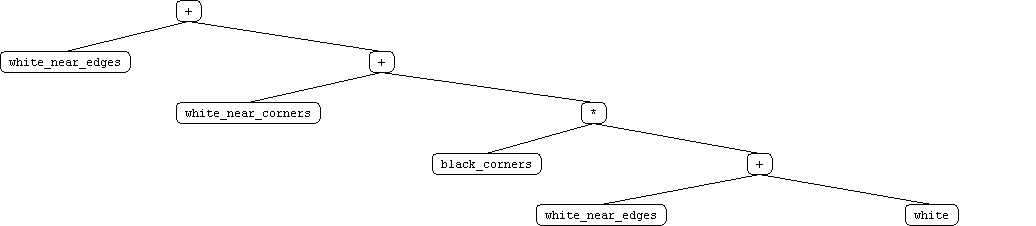
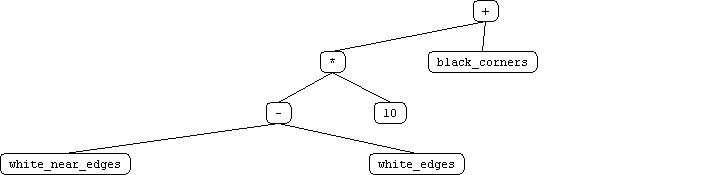
We attribute this to these possible factors: 1) human player looses general concentration 2) human player focues on one feature and forgets to focus on another 3) human player loses morale (ie if edgar takes a corner) 4) human player modify strategy as he plays We also beleive that whenever the hypothesis is changing, the performance inherently suffers in the short run, but improves in the long run. Test user 1 illustrates this point. the last 4 games were a contant improvement, where previous games had more sporratic improvement streaks. Our approach was fairly effective. We reduced the tree representation in accordance to what humans beleived to be important features. The features we selected were: near edges and near corner spaces, nothing else. using only these 4 features, we managed to derive a GP agent that could beat EDGAR taking 34% less copmutation time. We tried adding the new terminals without removing the default terminals. The runtime performance was better, but it was not able to generate an agent that could beat EDGAR. We conclude that a more complex terminal representation added more noise to the function tree representation. It can be concluded that a winning startegy is not directly related to number of the features. Instead, the selection of these features is non-arbitrary. One effective means to approach feature specifitcation seems to be through datamining on humans or expert systems. As aforementioned the features used to train the GPOthello player were derived from human subjects. These human test subjects were trained against EDGAR. Their distilled strategy, as encapsulated by the four terminals were specialized to beat EDGAR. Unlike EDGAR, these strategies do not generalize to play human opponents. This can be verified by actually playing the GP agent. Initial test results indicate that every human that has played it can defeat it quite easily. |
|
Appendix Play against
the trained GP that spanked EDGAR <here> |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
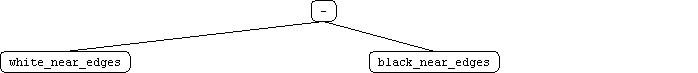{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}