
Figure 7-1. No communicative goal. User-supplied view specification.
The methodology presented in this thesis is designed to be both general and appropriate for a wide range of object domains and applications. This chapter describes how our system is modified for new objects, new rules, output media, and a completely new application. We show how the army radio object domain is augmented to include the battery pack. Then, we describe how an object domain is created. First we describe a simple office safe world and then the dice domain. Then we describe how to apply our methodology to support a completely new application, KARMA. KARMA (Knowledge-based Augmented-Reality for Maintenance Assistance)[Feiner et al. 92, Feiner et al. 93] provides explanations to a user wearing a see-through head-mounted display upon which graphics are projected to enhance the user’s view of the real world. We will show how IBIS can be adapted to meet the different sets of requirements presented by the KARMA system, ranging from the type of interaction to output display. We end this chapter with a discussion of implementation issues. Throughout the chapter, the reader is urged to evaluate the general methodology with regard to openness, reusability, and generality. Consider how the four main characteristics of the methodology presented in this thesis are appropriate for a wide range of applications and systems that require effective visual communication. These characteristics are 1) the separation of design from style, 2) the system of methods of evaluators, 3) the multi-level representation of an illustration and 4) the dynamic relationship between all components.
When adding a new object, the most time-consuming task is to model the object. For example, the battery pack consists of over a dozen objects: its sides, latches, connector, and main battery. A representation is generated for each one. We created three new shapes: latch, connector, and primary battery, and used preexisting shapes to model the sides and screws. All of these objects require position information, and six objects required different sets of instances or state information. Each of the four latches is represented in two states (snapped and unsnapped), the primary battery is represented in two states (in, out), and the battery pack is represented in two states (attached and unattached). Recognizability constraints are introduced for each object. Each latch shares the same recognizability constraint that specifies that a latch be viewed from an angle that enables the front face to be shown along with two other faces.
All aspects of the object representation are subjective and incomplete. The geometric model approximates the shape and surface of each object by omitting certain details. Similarly, the material definition is not exact. The individual who models these objects makes subjective decisions when creating the object model. It is best if he or she builds these models using knowledge about the rendering capabilities of the output device and his or her knowledge of the object.
Similarly, the individual providing the recognizability constraints should consider the semantics of the objects represented, the capabilities of the output device, and how the objects will be used to illustrate concepts. For example, in one domain an object may be recognizable because it is clearly labeled and the user knows that it is the only object manufactured by a certain company, while in another domain, that same object may be recognizable because it is the only object of that color. Again, the recognizability constraints are an imprecise means for a system to determine whether or not a user viewing a particular visual representation of the object will be able to recognize it. However, if the object representation is rich, the system can, when no specific rules are applicable, select properties to distinguish objects. (For example, in Chapter 3, we showed how an object may be classified as a landmark object using general criteria.)
New objects may require new rules for the new concepts related to these objects. For example, when we add the battery pack to the radio model we can chose to add “latch”-specific or “connector”-specific rules. For example, we can specify that the preferred method for showing the concept “snapping” of the latches is to generate the arrow and ghost combination applied in Figure 5-14 in Chapter 5. This can be accomplished by introducing a new design rule to handle “snapping” for latches. As we showed in Chapter 5, we can arrive at the same solution without the specialized rule. The general design methods for showing the state of an object were applied with the same results. This is because the selected design rule specifies that a meta-object be generated to show the object movement, and that a ghost image of the object in the previous state be added.
There are cases, however, when we prefer that a particular solution be used. Specialized rules are treated as preferred rules and are tried first. However, there are many different ways we can alter the rule base so that a particular method is preferred. We can add a rule that specifies that showing the state “snapping” should be accomplished using the meta-object, ghost combination. However, this does not guarantee that the meta-object chosen will be the straight arrow. We can add yet another rule that specifies that the preferred meta-object for showing the state “snapping” is a straight arrow. This introduces problems when we wish to illustrate the “snapping” of someone’s fingers. We can alternatively opt to add the object class (“latch”) to further specialize the rule for using the straight arrow. But, certain latches may snap in different ways. To solve this problem, we can use the information provided in the object model to differentiate the different latches and the way a particular one should be illustrated. Therefore, the introduction of specialized rules is to be avoided unless necessary. Specialized rules are introduced to handle complex object movement or changes in state (that cannot be handled by the primitives provided) and to impose conventions in style and design. We will show in the next section how specialized rules are necessary when the selection of a design or style must be based on the semantics of an object (as opposed to its physical properties). In all cases, the use of specialized rules enables the illustration system make selections using more knowledge during the design process. This frees other modules from the responsibility of representing knowledge that determines how concepts are depicted visually.
In the previous example, the object domain was enhanced and no new rules were introduced. We emphasized that it was not necessary to change the rule base to handle new objects. Both COMET and IBIS were designed to handle different object domains. In this example, we will replace the army radio object domain with new ones. In the first we will show that no modification to the rule base is necessary to illustrate existing concepts. In the next example we will show that the new object domain has new concepts associated with it that require new rules.
When the system is started up, an object domain is loaded in.
We can create a new object domain, load it in and use the system
to generate illustrations without any modification to the rule
bases. To show how easy it is to create a new domain, we have
created a very simple world with minimal effort. It contains
an office safe, which
Figure 7-1. No communicative goal. User-supplied view specification.
consists of a door, a combination lock, some interior shelves, gold bars, and an alarm bell. The door, gold bars and shelves are made of rectangular shapes in different materials. It took less than one hour to create the file with each object’s representation. Immediately, the new domain can be loaded into the system and the user can navigate using the interface described in Chapter 6. The user selects the view specification and the resultant illustration is shown in Figure 7-1. We specify a location goal for each gold bar, and IBIS generates the cutaway views revealing each bar as shown in Figure 7-2. We specify a location goal for the alarm; the resultant illustration is shown in Figure 7-3.

Figure 7-2. Communicative goal: show location of gold bars. User-supplied view specification.
We created the dice domain (shown in the Figures in Chapter 1) by introducing a new object type “die.” The shape “die” consists of six faces, each with a different configuration of dots. We created a subclass of die called “loaded die.” A loaded die has an additional subpart, the weight imbedded in its body. We added a table top to complete the dice object domain. A simple block shape is used for the table and the weight shapes. For each object we added recognizability constraints. Determining the recognizability of a die requires that we think about what it is that makes a die a familiar object. We decide that what makes a die a die, is the configuration of the dots on the six faces. We design the recognizability constraints to reflect these two properties. First, we can show three mutually contiguous faces to imply that there are six, and we can specify that the dots on each face be legible (which also might fail if the dots are unusually shaped). The recognizability information specifies the eight different angles from which three faces can be seen (as shown in Figure 7-4) and the minimum area occupied by a dot. These constraints can be used by any object of type die. For the weight we specified that the material be shown and that the weight be seen so that three faces show. For the table top we specified that the top face and any other two side faces be shown.

Figure 7-3. Communicative goal: show location of gold bars and alarm.
User-supplied view specification.
One of characteristics we might want to illustrate about our dice is the value of a “roll.” We therefore add a new concept to our system: the “roll” of the dice, which we will list as a property of objects of type die, but which requires two dice. A roll has no meaning unless the two dice are in a state we will call “at rest.” We provide a function to determine if the dice are at rest (which checks if the position information is stable). In order to show the value of the roll we introduce a specialized rule to apply a certain convention. It specifies that to show the property of “roll” the dice must be viewed from above (straight down the y-axis). This rule constrains the view specification. Thus, we have introduced a concept specific rule for showing the dice’s “roll,” and we have added the condition that this concept cannot be shown unless the dice are in a particular state. Suppose we specify that the communicative goal is to show the dice. We add another communicative goal which it to show the property “roll.” These two rules are sufficient for generating an animated sequence (with position information supplied by a simulator) in which the dice are shown falling on a table, coming to a rest, and an inset popping up to show the roll, as shown in Figure 1-3.
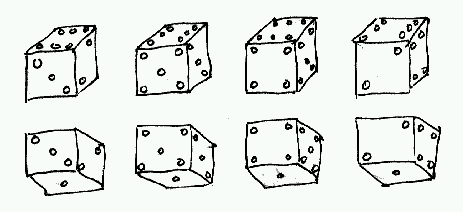
Figure 7-4. Recognizability constraints for each die.
Up to this point, we have demonstrated how our system designs 3D color illustrations for a high-resolution graphics display. In Chapter 6 we showed how our system supports several interactive capabilities and how each illustration is dynamic. In this section we show how our architecture is enhanced to support an interactive system in which goals, objects, and the view specification can change at the same time.

Figure 7-5. Blair MacIntyre using KARMA.
The KARMA system generates illustrations on a see-through head-mounted display, explaining tasks to a user moving about in the real world. The user’s head movements are monitored by a 3D tracker attached to the user’s headpiece. Other trackers are placed on various objects in the room. The illustrations are presented onto the see-through display and thus appear over the user’s view of the world. Figure 7-5 shows Blair MacIntyre using the system. IBIS’s task is to design the illustrations that appear on the see-through head-mounted display to augment the user’s view of the world. The illustrations are designed to achieve communicative goals to enhance the user’s understanding of his or her surroundings, illustrate concepts related to the objects in the environment, and explain tasks the user can perform (or is expected to perform) on the objects.
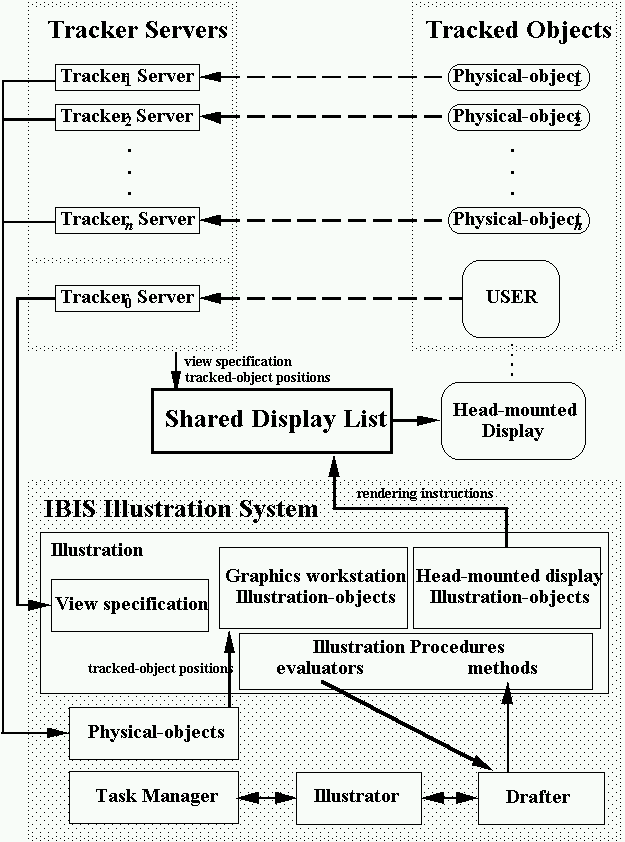
Figure 7-6. IBIS in KARMA.
Figure 7-6 shows KARMA’s overall architecture and the internal changes in IBIS’s architecture needed to accommodate it. The graphics that appear on the see-through mounted display must change as both the user and objects move in the real world, so that the graphics are correctly positioned over objects. Therefore, the graphics require constant updating, responding to the user’s head movements as well as the objects’ movements. For this reason, KARMA has a separate display server that maintains and renders the objects in a shared display list. This server is a client of the tracker servers that report the position of both the user’s head and the tracked objects. Some of the objects in the display-list correspond to the objects in the real world. As the trackers report new positions for these objects, the corresponding graphical objects are updated. Similarly, the viewing transformation matrix is constantly updated to reflect the user’s new head position. IBIS creates the objects in the shared display list, specifying a tracker identity with which the object is associated. But, IBIS is a client of the tracker server as well. IBIS uses the most recent tracker values in order to create, set and reset, and position the objects in the shared display list. IBIS, therefore, runs synchronously from the display server, and the illustrations IBIS designs are based on the last values it retrieved.
IBIS has two tasks and uses two separate representations of the world to accomplish each. The first task is to design the graphics that are displayed on the head-mounted display, the second task is to generate the commands that create the bi-level graphics presented on the head-mounted display. IBIS maintains two types of illustration-objects for the objects in the world, both based on the same object representation. The first set, the graphics workstation illustration-objects, represent the world and correspond to the illustration-objects described in the previous chapters. They are used during the design process to determine object visibility and screen size, using the graphic workstation’s framebuffer and z-buffer. They are used when illustration evaluation procedures are called. These objects are used to determine what the user is looking at, what objects are occluded, and when objects reach a certain state. The second set of illustration-objects, the head-mounted display illustration-objects, define the objects that are rendered on the see-through head-mounted display. They are generated when illustration method procedures are called. They are the bi-level graphics that are displayed over the user’s view of the world.
Thus, IBIS maintains two internal representations of the world. The first represents what the user sees of the real world and the second represents what the user sees projected on the see-through display. Together, the two sets of illustration-objects represent the user’s augmented reality: the graphics workstation illustration-objects represents the user’s view of the real world; the head-mounted display illustration-objects represent the enhancements made to the user’s view of the real world.
The head-tracker reports the current position which is used to set the view specification associated with the graphics workstation illustration-objects. The object trackers report the current object positions which are used to update the graphics workstation illustration-objects. Each time something changes, all active evaluators are reevaluated. For example, if the illustrator determined that an object must be visible, then the object’s visibility is determined and the illustration is redesigned if necessary.
The KARMA user is a very active participant in achieving communicative intent. For instance, if the communicative goal is to get the user to perform an action, then this must be communicated to the user, and the goal is evaluated as successful once the user completes the action. As we have shown in the previous chapters, IBIS’s architecture enables it to determine when objects reach a certain state. The same mechanisms that are used to detect when objects reach a particular state are used to monitor the user and determine when goals are accomplished. The types of communicative goals used by KARMA range from getting a user to approach an object, to getting the user to manipulate an object.
In KARMA, IBIS evaluates the success of a communicative goal by considering both the evaluations for the illustration as well as the user’s actions and changing states of objects in the world. In the COMET domain a content planner and media coordinator determine what should be communicated based on the interaction with the user [Feiner and McKeown 90, Feiner and McKeown 91]. In KARMA, IBIS monitors the world and user and uses this information to determine whether or not certain actions have been completed. Using this information, IBIS independently changes its goals and breaks down high level tasks into a set of subtasks if necessary. For example, in COMET, the user is presented with a description of tasks. The user can ask for a task to be described in greater detail. The resultant explanation consists of a series of steps. In KARMA, a communicative intent requires that the user manipulate an object. On the basis of the user’s actions, IBIS determines, itself, if it is necessary for the user to complete intermediary tasks such as locating the object.
Tasks can also be specified as a set of specific substeps. Communicative goals are grouped together to represent the steps in a particular task. A task consists of an ordered set of substeps. Figure 7-7 shows task management as a simple extension to
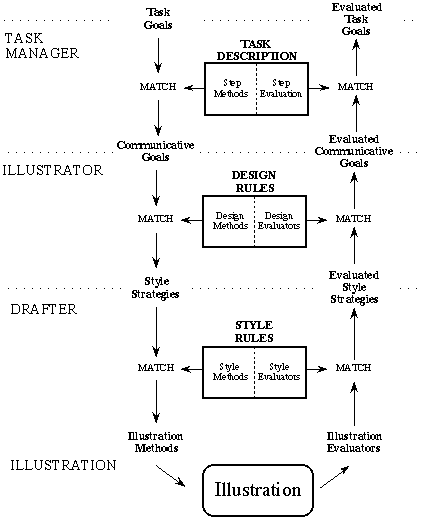
Figure 7-7. Illustration Process in KARMA.
IBIS’s architecture. We create a new component, the task manager, to step through a task description. The object domain for KARMA is the maintenance and repair of a laser printer. Figure 7-8 shows the subtasks for removing the paper tray. The task manager assigns communicative goals for the current subtask to the illustrator and the illustrator reports the success of each goal. When each assigned goal is evaluated to be successful, then the task manager deactivates the current set of goals and proceeds to the next subtask. This mechanism is simply an extension of the general mechanisms for continuously evaluating the current state of the illustration.
(step 1 show Printer highest)
(step 1 identify Printer highest)
(step 2 action PrinterTray out highest)
(step 2 identify PrinterTray highest)
Communicative goals have a slightly different meaning in the KARMA domain because of the user’s new role in the achieving a goal. We describe six communicative goals and the style strategies and rules used to achieve them.
The KARMA user actively participates in accomplishing the communicative goal show by looking at the designated objects in the real world. We show an object to someone by making it visible to that person. We can do this directly, by putting the object in the other person’s field of view or by leading the person to the object. For example, we point to someone in a crowd or wave something in front of someone’s eyes. We can show a dress by simply wearing it and parading in front of the viewer. In order to accomplish the show goal in KARMA, the system must determine whether or not the object is visible to the user.
Figure 7-9 shows two design methods that are used to show an object. Figure 7-10 shows two design evaluators used to determine when an object is successfully shown. The goal succeeds only when the user can see the object. The first method sets up a visible style strategy for the object. Figure 7-11 shows the style method for visible and Figure 7-12 shows the style evaluators for visible. Illustration procedures are capitalized and are called directly from the left and right hand side of the rules. If the object is in the user’s view and no objects occlude it, the goal is evaluated as successful. If the object is in the user’s view, but is occluded by other objects, a line drawing is generated in the dashed “OCCLUDED” line style and the goal is evaluated successful. If the object is not in the user’s view then the goal fails. The illustration procedure for determining an object’s visibility is unmodified (and is the same one described in Chapters 3 and 4). The head-tracker provides the view specification and the graphics workstation illustration-objects representing the real world are used to detect occlusion and presence in the view volume.
(design-method-1-for-the-goal-show
;; ASSIGNED TO THE ILLUSTRATOR
(show ?object highest)
=>
;; ASSIGN TO DRAFTER
(visible ?object highest)
)
(design-method-2-for-the-goal-show
;; ASSIGNED TO THE ILLUSTRATOR
(show ?object highest)
;; REPORTED FROM THE DRAFTER
(evaluated visible ?object fail)
=>
;; ASSIGN TO THE DRAFTER
(find ?object highest)
)
(design-evaluator-1-for-the-goal-show
;; REPORTED BY THE DRAFTER
(evaluated visible ?object success)
=>
;; REPORT TO THE TASK MANAGER
(evaluated show ?object highest)
)
(design-evaluator-2-for-the-goal-show
;; REPORTED BY THE DRAFTER
(evaluated find ?object success)
=>
;; REPORT TO THE TASK MANAGER
(evaluated show ?object success)
)
The second method is selected by the illustrator that asserts a find style strategy. The style method shown in Figure 7-13 specifies that a label and leader line be generated. This leader line will extend beyond the user’s current view. If followed, it leads the user to the object.
(style-method-for-visible-in-KARMA
;; ASSIGNED TO DRAFTER
(visible ?object highest)
;; CALL ILLUSTRATION EVALUATORS
(evaluate ((Visible ?object) == TRUE))
(evaluate ((Obscured ?object) == TRUE))
=>
;; CALL ILLUSTRATION METHOD
(InteriorStyle ?object)
)
(style-evaluator-1-for-visible-in-KARMA
;; ASSIGNED TO DRAFTER
(visible ?object highest)
;; CALL ILLUSTRATION EVALUATORS
(evaluate ((Visible ?object) == TRUE))
(evaluate ((Obscured ?object) == FALSE))
=>
;; REPORT TO ILLUSTRATOR
(evaluated visible ?object success)
)
(style-evaluator-2-for-visible-in-KARMA
;; ASSIGNED TO DRAFTER
(visible ?object highest)
;; CALL ILLUSTRATION EVALUATORS
(evaluate ((Visible ?object) == TRUE))
(evaluate ((Obscured ?object) == TRUE))
(evaluate ((InteriorStyle ?object) == TRUE))
=>
;; REPORT TO ILLUSTRATOR
(evaluated visible ?object success)
)
(style-evaluator-3-for-visible-in-KARMA
(visible ?object highest)
(evaluate ((Visible ?object) == FALSE))
=>
;; REPORT TO ILLUSTRATOR
(evaluated visible ?object fail)
)
(style-method-for-find -in-KARMA
;; ASSIGN TO DRAFTER
(find ?object highest)
;; RETRIEVE FROM OBJECT REPRESENTATION
(label-text ?object ?text)
=>
;; CALL ILLUSTRATION METHOD
(CentralLabel&LeaderLine ?object ?text)
)
A KARMA user may be looking at an object, yet may not know what that object is. The identify goal is accomplished by positioning an identifier object over or near the object. Currently we support only textual labels, but icons could be used as well. The contents of the textual label can be determined by a natural language generation module or hardcoded in the task description. Thus, different names may be used depending on different events. For example, the task to replenish the paper supply may refer to the “empty paper tray” rather than simply the “paper tray.” Figure 7-14 shows the design method that asserts visible and label goals. Figure 7-15 shows the style methods for labeling an object. The first specifies a label, that is positioned on the boundary of the illustration with a leader line pointing to the object. The second specifies a label that is positioned over the object. In the current implementation, the evaluations for labeling return success once the label is set in the shared display list. Figure 7-16 shows the illustration IBIS generates to identify the paper-tray.
(design-method-1-for-identify-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(identify ?object highest)
=>
;; ASSIGN TO DRAFTER
(visible ?object highest)
(label ?object highest)
)
The reference goal is achieved by labeling the object as shown in Figure 7-17.
The change goal is to illustrate how an object changes state. Figure 7-18 shows a design method that species that the specified state of the object be depicted in a ghosted manner. As described in Chapters 4 and 5, a ghosted version of the object is on the high resolution color display is accomplished using transparency. In KARMA, a dotted “GHOST” line-style is assigned to the line segments that represent the object in the specified state. Thus, ghosted objects appear fainter than other objects that have been outlined in solid line styles. Figure 7-19 shows the style method for ghosting.
(style-method-1-for-label-in-KARMA
;; ASSIGNED TO DRAFTER
(label ?object highest)
;; RETRIEVE FROM OBJECT REPRESENTATION
(label-text ?object ?text)
;; CALL ILLUSTRATOR EVALUATOR
(evaluate ((Visible ?object) == FALSE))
=>
;; CALL ILLUSTRATION METHOD
(CallOutLabel ?object)
)
(style-method-2-for-label-in-KARMA
;; ASSIGNED TO DRAFTER
(label ?object highest)
;; RETRIEVE FROM OBJECT REPRESENTATION
(label-text ?object ?text)
;; CALL ILLUSTRATION EVALUATOR
(evaluate ((Visible ?object) == TRUE))
=>
;; CALL ILLUSTRATION METHOD
(ObjectLabel ?object)
)

Figure 7-16. Communicative intent: identify paper-tray
(design-method-1-for-reference-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(reference ?object highest)
=>
;; ASSIGN TO DRAFTER
(label ?object highest)
)
(design-method-1-for-change-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(change ?object ?other_state high)
=>
;; ASSIGN TO DRAFTER
(ghost ?object ?other_state highest)
)
(style-method-1-ghost-in-KARMA
;; ASSIGNED TO DRAFTER
(ghost ?object ?other_state highest)
=>
;; CALL ILLUSTRATION METHOD
(Ghost ?object ?other_state )
)
The action goal is to get a user to perform some action in the real world so that an object reaches a certain state. The main difference between the action goal and the change goal is that the user is an active agent in the goal's success. The action goal is not evaluated to be successful until the user satisfies the goal or successfully completes the action. The first design method shown in Figure 7-20 is designed to get a user to perform an action with high priority. The method specifies three subgoals: visible, ghost, and move. The move goal is used to depict how the object is to manipulated. Moving is depicted using one of two arrow styles: straight and arc. These arrows are not static, but are displayed as moving to show how the object is to move. The animated arrow, is intended to draw the user’s attention to it. Figure 7-21 shows the illustration IBIS designs to identify the paper tray and show how it is to be removed.
(design-method-1-for-action-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(action ?object highest)
=>
;; ASSIGN TO DRAFTER
(move ?object highest)
(ghost ?object highest)
(label ?object highest)
)
(design-method-2-action-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(action ?object low)
=>
;; ASSIGN TO DRAFTER
(move ?object highest)
)
We have described how our system uses state information to determine when object reach known states. The style evaluator shown in Figure 7-22 for the move goal calls on an illustration procedure that performs this test. When the object reaches the specified state the goal is evaluated successful. Similarly, as shown in Figure 7-22, the design evaluator for the action goal returns success only when the move goal is evaluated as successful.

Figure 7-21.Communicative intent: action remove paper-tray, identify paper-tray
The second design method shown in Figure 7-20 is specified with low priority, which means that it really is not very important that this goal succeed right away. This level of importance corresponds to, for instance, a situation in which someone is asked to pick up a newspaper if they happen to go near a newsstand. If the user passes a newsstand, then the method is activated to show the user what to do. The user is fully participating in the goal's success and the goal will not be evaluated as successful until the system detects that the object has reached the desired state. The method specifies only a move goal. The arrow that is generated to show the action will appear on the see-through display only when the user looks toward the object.
(style-evaluator-1-move-in-KARMA
;; ASSIGNED TO DRAFTER
(move ?object ?state)
;; CALL ILLUSTRATION EVALUATOR
(evaluate ((State ?object) == ?state))
=>
;; REPORT TO ILLUSTRATOR
(evaluated move ?object ?state success)
)
(design-evaluator-1-action-in-KARMA
;; ASSIGNED TO DRAFTER
(evaluated move ?object ?state success)
=>
;; REPORT TO ILLUSTRATOR
(evaluated action ?object ?state success)
)
The action goal need not be limited to the KARMA domain. Were the user to manipulate the graphical objects depicted in the COMET domain, the action goal would be used to monitor the user's interaction with the modeled objects. The actual object could be monitored or the user could use a simple interface to manipulate the graphic. For example, the action of turning a dial would be monitored by the system and evaluated as successful once the dial reached the desired state. This mechanism would be useful for interactive tutorials, simulations, and testing.
Figure 7-24 shows design methods for the location goal. The location of an object is shown by drawing it in a special highlight line style. The user is led to first look towards the object if necessary. Once the user looks toward the object, the object appears with a bright outline. The highlight method shown in Figure 7-25 specifies that the object be drawn in the highlight line style.
(design-method-1-location-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(location ?object highest)
=>
;; ASSIGN TO DRAFTER
(highlight ?object highest)
)
(design-method-2-for-location-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(location ?object highest)
=>
;; ASSIGN TO DRAFTER
(find ?object highest)
(highlight ?object highest)
)
(style-method-1-for-highlight-in-KARMA
;; ASSIGNED TO ILLUSTRATOR
(highlight ?object highest)
=>
;; CALL ILLUSTRATION METHOD
(Highlight ?object )
)
IBIS is written in C++, the CLIPS production system language [Culbert 91], and uses the HP Starbase graphics library, the X Window System, and Motif. It runs under HPUX on a HP9000 375 CRX48z graphics workstation, which includes a hardware z-buffer. IBIS also generates overlaid graphics on a see-though head mounted display that uses a Reflection Technology Private Eye. IBIS populates and manipulates the display list for the head-mounted display using a graphics package written by Blair MacIntyre in C.
The decision to use CLIPS was based on three major considerations: speed, readability, and compatibility. Graphics systems require a lot of information. We had to find ways to separate this information from the mechanisms that conduct the inferencing. In the COMET domain, the knowledge-base is written in LOOM[MacGregor and Brill 90]; however, we chose to separate all the geometric information for the radio. We developed shape libraries so that the complete representation of the radio was not encumbered with long lists of coordinates (thus, the description of the entire radio, including state information, fits on ten pages). Another obstacle concerns maintaining the state of the radio. We chose to represent states separately as differences from a base state. For example, the state information for a radio dial consists of rotation value and keyword. We later chose to incorporate such knowledge, as well other other-specific knowledge in the actual rule-base. This did not require much space and made retrieval more efficient. CLIPS allows C and C++ procedures to be called directly from both the left-hand and right-hand side of rules. This makes it straightforward to incorporate the illustration procedures into the inferencing portion of the system. The most difficult task was to implement backtracking and at the same time exploit the functionality (and efficiency) provided by CLIPS. The difficulties we encountered lead us to believe that there is a serious need for rule-based languages that make encoding dynamically changing backtracking schemes and salience easy. Another issue concerns the representations used by the different media generators in COMET. While the graphics generator’s representation and descriptions are based on specific objects, the content planner and text generator describes concepts and need not refer to a specific object. We wrote a preprocessor to map concepts (that referred to types of physical-objects) to the physical objects in our object-base so that they could be illustrated.
We have imposed one major limitation on the types of objects handled: IBIS handles only rigid polygonalized objects.
Our methodology is based on general notions about illustration. Consequently, the approach is applicable to a wide variety of domains and illustration tasks. In this chapter we have shown how the system can be extended to handle new objects, concepts, and object domains. We have also described steps we took to create an enhanced version of IBIS to generate illustrations for KARMA. We have shown that although KARMA is very different from COMET, our architecture is able to expand to handle new tasks, a completely different output display, new goals, and most importantly, a new level of interaction.
When IBIS was adapted for KARMA we discovered that the evaluation mechanisms could be used to monitor the user’s actions and determine what he or she was looking at in the real world. We altered IBIS’s rule base to exploit these mechanisms. Evaluations in KARMA would return successful when the user, by his or her actions, indicated that communicative intent was successful. For example, if the communicative intent was to get the user to locate an object, the location goal would be evaluated as successful when IBIS detected that the user had “found” the object. Similarly, if the communicative intent was to get the user to perform some action on some object, the action goal would be evaluated as successful when IBIS detected that the object had reached the specified state. The user is an active participant to achieve communicative intent. The user of sensors and evaluations of the user’s movements, enables us to determine if communicative intent is achieved.