3D Photography Class ProjectSpring 2005 |
This is the homepage for the Decomposers team from Dr. Peter Allen's 3D Photography class at Columbia University.
The team consists of Matei Ciocarlie and Corey Goldfeder, both students in Dr. Allen's Robotics Lab .
We are implementing a full pipeline for automated robotic grasping, from initial sensing to final grasp execution.
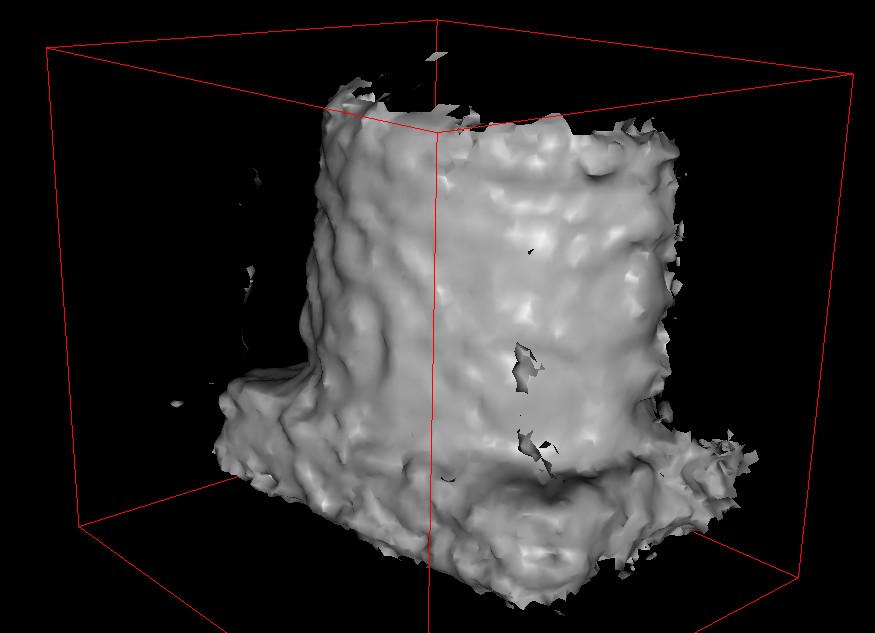
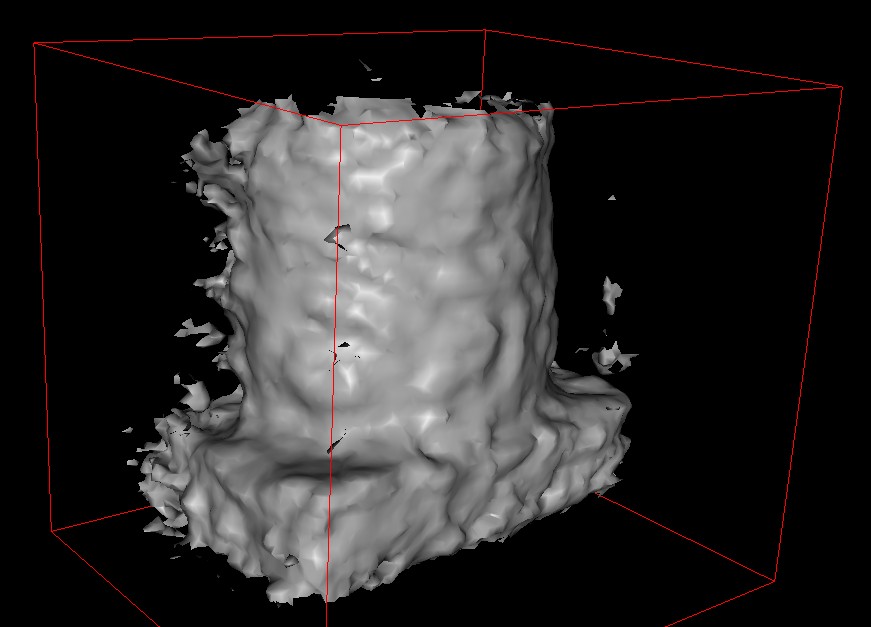
1. The first step in our pipeline is the acquisition of a model of the object to be grasped. For this we are using a Canesta real-time 3D sensor. Combined with a positional tracker, the sensor allows us to construct an approximate 3D model in real time. Matei has written software to automatically register and combine multiple views from the Canesta into a single mesh.
Here are some screenshots of the models constructed from the Canesta:
These results will be cleaner in the final project.
2. The next step is to segment the model into basic components. In the papers list below, we have referenced several segmentation methods. We have not finalized this stage yet.
3. The third step is to fit primitives to each of the segmented components. Our primitives are cuboids, spheres, right cylinders and cones. Each of these primitives can be approximated by a superquadric function with the proper parameters. (See the references below for more about superquadrics.) We use a levenberg-marquadt least-squares minimization routine to fit each of the four primitives to the data, and then choose the primitive of the four with the best fit. The primitive parts are then combined to give a primitive representation of the object.
These results will be cleaner in the final project.
4. Finally, we feed the primitives and original mesh file into the GraspIt grasp planning software (referenced below) and plan an automated robotic grasp of the object.
5.Sometime in the near future, but after the end of this class project, we hope to implement the grasp in hardware with a real hand, to finish our pipeline.
| Approximate Convex Decomposition of Polyhedra |
| Jyh-Ming Lien, Nancy M. Amato |
| Technical Report, TR05-001, Parasol Lab, Texas A&M |
This paper presents an algorithm for breaking a model into approximately convex parts. This is good for us; approximate convexity, as opposed to real convexity, means both that there can be error tolerance in the decomposition and that small features, hopefully suitable for matching against, remain even in the decomposed parts. |
| Approximate Convex Decomposition |
| Jyh-Ming Lien, Nancy M. Amato |
| Proc. ACM Symp. Comput. Geom., pp. 457-458, Brooklyn, New York. June 2004 |
Another paper on the same subject as the one above. |
| Partitioning 3D surface meshes using watershed segmentation |
| Mangan, A.P., Whitaker, R.T. |
| IEEE Transactions on Visualization and Computer Graphics 5:4, Oct.-Dec. 1999 |
This is here for completeness - we are aware of other segmentation methods - but it's not robust enough for what we need. |
| Superquadric Representation of Automotive Parts Applying Part Decomposition |
| Y. Zhang, A. Koschan, and M. A. Abidi |
| Journal of Electronic Imaging, Special Issue on Quality Control by Artificial Vision, 13:3, July 2004 |
They use a curvature decomposition and then superquadric recovery to describe complicated automotive parts. Important point: they recover superquadrics from a mesh, which is what we have, not a set of range points. It's somewhat unclear from this paper how exactly they do the recovery, although the decomposition is nicely spelled out. Unfortunately, it's not robust enough for what we want to do - Matei was able to construct almost immediately a test case which would fail our needs under this decomposition. Globally deformed superqaudrics might be great for a first pass filter of the data. They can be computed offline and searched fast. The downside is that they aren't sensitive to small local features - the only features we will have left after a convexity decomposition! On the other hand, we hope they can be used to quickly weed out 90% or so of the database, so that we can concentrate on more likely matches. |
| A Reflective Symmetry Descriptor for 3D Models |
| Michael Kazhdan, Bernard Chazelle, David Dobkin, Thomas Funkhouser, and Szymon Rusinkiewicz |
| Algorithmica, 38(2), November 2003 |
Using spherical harmonic functions, they (rotationally invariantly) decompose a shape into a symmetry descriptor, computed offline. Matching is then done in the space of these descriptors. This is pretty much the state of the art in shape descriptors right now. The lightfield descriptors paper claims an improvement over this method, but it's not applicable to us. Unfortunately, this may not be too applicable either. The essential feature that this method uses is a measurement of a shape's self-symmetry, which for a set of entirely convex objects may be fairly high. This might be good for us, and it might not be - it's still somewhat unclear. |
| The Princeton Shape Benchmark |
| Philip Shilane, Patrick Min, Michael Kazhdan, and Thomas Funkhouser |
| Shape Modeling International, Genova, Italy, June 2004 |
Very simply, this is a standardized database of 3D objects to test a shape matching algorithm against. It's used in a lot of the papers here and we plan to use it as well. |
| Shape Matching and Anisotropy |
| Michael Kazhdan, Thomas Funkhouser, and Szymon Rusinkiewicz |
| ACM Transactions on Graphics (SIGGRAPH 2004), Los Angeles, CA, August 2004 |
This is an intriguing discussion about resizing models to deal with anisotropy. The caveat we must keep in mind is that if we use this (and I don't see why we wouldn't) then all of the parts being matched to a particular object should have similar (within some error tolerance) anisotropy compared to the parts matched to them in the database. This isn't a major limitation - we can match naively and just add in that constraint at the same time we check for parts being in the same un-decomposed model. It's just something to be aware of. |
| 3D Shape Matching with 3D Shape Contexts |
| Marcel Kortgen, Gil-Joo Park, Marcin Novotni, Reinhard Klein |
| The 7th Central European Seminar on Computer Graphics, April 2003 |
The shape descriptors described here are essentially predecessors of the Princeton stuff. They aren't as robust, but they also aren't as dependant on symmetry. This is not my favorite choice, but it may be the best set of shape descriptors we're going to find for the job. |
| On Visual Similarity Based 3D Model Retrieval |
| Ding-Yun Chen, Xiao-Pei Tian, Yu-Te Shen and Ming Ouhyoung |
| Eurographics Volume 22 (2003), Number 3 |
The basic idea is that 2D silhouettes from various positions can describe a 3D object. They use 10 views, forming half of a regular dodecahedron around the object, and then chose an orientation so that there is maximum similarity. Note the simplifying assumptions of only 10 views, and of 256 x 256 view sizes. They try 60 orderings of corresponding images and choose the best one to solve for rotations, but this isn't robust enough to work so they use 10 different lightfield descriptors, at different orientations, and choose the best of the 10. In practice, this means they are discretizing angular space into cones of about 3.4 degrees. This is a fairly rough approach. Once this is done, shape matching is done strictly in 2D. My conclusions: This is a nice way of finding an object based on a 2D silhouette. However, it's fairly useless for us, since the individual parts after a decomposition will look very similar as silhouettes. It would also be a very slow for us, since we have to compare part by part. Their method of solving for rotations might be useful, but I can't see it working in our system. |
| A survey of free-form object representation and recognition techniques |
| R. Campbell and P. Flynn |
| Computer Vision and Image Understanding (CVIU), 81(2) 2001 |
This is a survey of several topics, but there is some good shape matching stuff in here. If we end up using a cocktail of weaker techniques, as I suspect we might, instead of settling on one or two good matching methods, we will likely draw from some of this material. |
| Parts-based 3D object classification |
| D. Huber, A. Kapuria, R.R. Donamukkala, and M. Hebert |
| Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 04), June, 2004. |
They break models of vehicles into 3 parts (front, middle, back) and match parts seperately. The models, which are known in advance to be vehicles, are pre-oriented and the segmentation is a crude slicing into thirds. The method they use for part matching is regional point descriptors. Good news: it seems to work. Bad news: the huge simplifications, particularly the pre-orientation of the model, means that it's impossible to seriously compare this to other work. Also, the segmentation was done in a way which left a lot of features in each part, while our segmentation method will produce much more "featureless" parts. Nevertheless, it's a good place to start, and there's a nice survey of part matching here. |
| Superquadrics for segmenting and modeling range data |
| A. Leonardis, A.Jaklic, F. Solina |
| IEEE Transactions on Pattern Analysis and Machine Intelligence, 19.11 1997 |
This paper discusses fitting superquadrics to range image point clouds. |
| Recovery of Parametric Models from Range Images: The Case for Superquadrics with Global Deformations |
| F. Solina, R. Bajcsy |
| IEEE Transactions on Pattern Analysis and Machine Intelligence, 12.2 1990 |
The cone primitive is a deformed cylinder, so this was useful. |
| Segmentation and Recovery of Superquadrics |
| A. Leonardis, A.Jaklic, F. Solina |
| 2000 Kluwer Academic Publishers |
A book on the same subject as the above papers. |
| GraspIt!: A Versatile Simulator for Grasp Analysis |
| Andrew Miller, Peter K. Allen |
| Proceedings ASME International Mechanical Engineering Congress & Exposition, November 2000 |
The GraspIt! simulator can plan a grasp on an object if it has a primitive representation. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}